Mirage: The Virtual Filesystem Resolving One of the AI Agents' Biggest Problems
There is a problem that anyone who has ever tried to build a serious AI agent knows well. It's not the model — models today are excellent. It's not the reasoning — modern LLMs reason in a surprising way. The problem is data access. Every service has its own API, every platform has its own SDK, every backend requires different authentication, different calls, different error handling, and different pagination. An agent that has to work with S3, Google Drive, Slack, Gmail, GitHub, and a Redis database at the same time ends up bringing a huge amount of technical complexity into the context before even starting to do anything useful. Mirage attacks this problem at the root, and it does so with an idea that is elegant in its simplicity: turning everything into a filesystem.
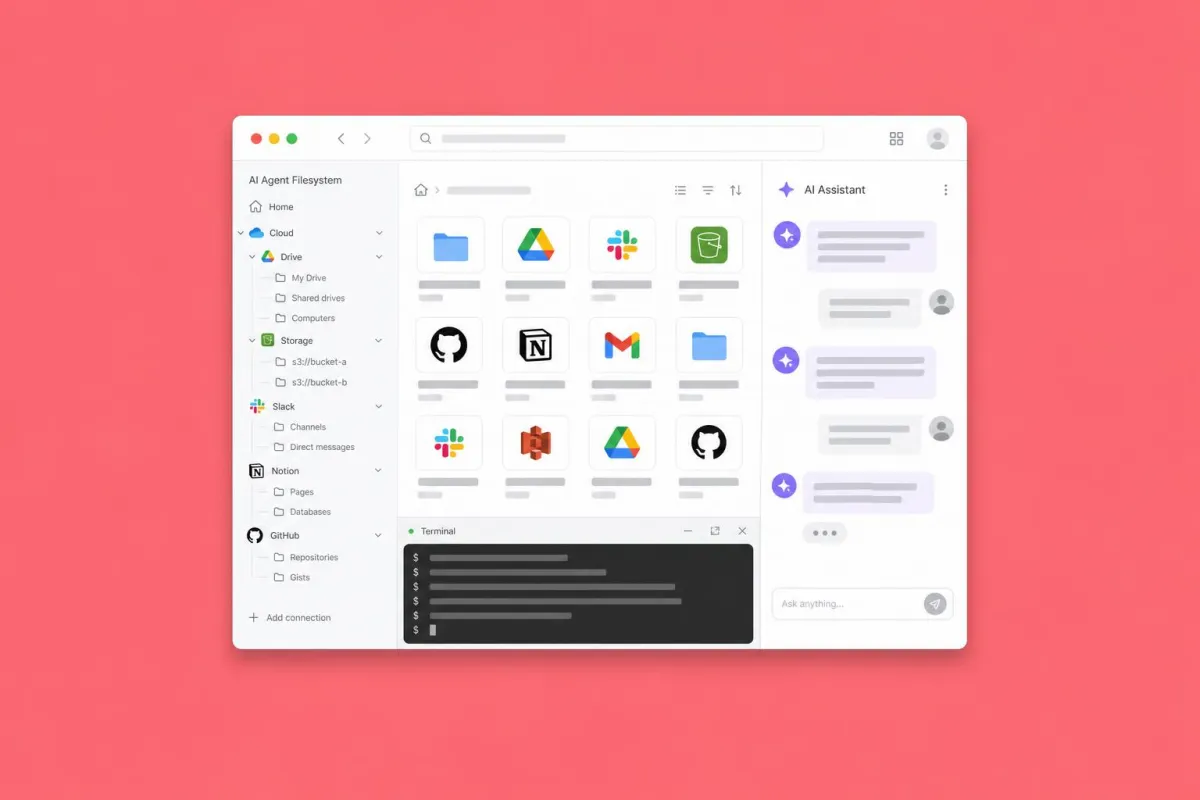
Mirage is a unified virtual filesystem for AI agents, developed by Strukto.ai and released as an open-source project under the Apache 2.0 license. The central concept is what is called 'mount' in Unix: instead of calling different APIs to access different services, Mirage mounts every service as a folder within a single directory tree. S3 becomes /s3, Google Drive becomes /gdrive, Slack becomes /slack, Gmail becomes /gmail, GitHub becomes /github, Redis becomes /redis — and so on for all supported services.
Once mounted, all these backends behave as if they were folders on a local disk. The AI agent can use the same Unix commands it uses for any filesystem: ls to list contents, cat to read a file, grep to search text, cp to copy data from one service to another, head to read the first lines of a document. There is no new vocabulary to learn, no new patterns to memorize. It's bash. And language models already know how to use bash better than any other interface because it's the system they were trained on most intensively.
The Strukto.ai team rewrote bash from scratch in 1.1 million lines of code to make it work in this context. This isn't just a rough compatibility layer: it's a complete implementation that makes cat, grep, head, and pipes work directly on .parquet, .csv, .json, and even .wav files, regardless of where those files physically reside.
To understand why Mirage is relevant, it's worth concretely describing the problem it solves. A typical AI agent in a corporate context must work with dozens of different systems. It needs to read documents from Google Drive, check emails on Gmail, access data on S3, consult tickets on Linear or Jira, read code on GitHub, query data on MongoDB, use caches on Redis, and communicate on Slack.
Without an abstraction layer, every single one of these integrations requires a separate SDK, separate authentication management, a separate set of tools to be included in the agent's prompt, and separate error handling logic. The result is what developers call 'tool-schema sprawl': the agent's prompt fills up with dozens of tool definitions, each with its own parameters, edge cases, and usage patterns. The model must keep all this in context while trying to reason about the main task. It's a huge cognitive load that directly degrades the quality of reasoning.
Mirage collapses all this complexity into a single abstraction: the filesystem. Instead of N SDKs and M MCP configurations, the agent sees one thing — a directory tree — and uses the same five or six bash commands to access any backend. The complexity doesn't disappear: it is moved inside Mirage, outside the agent's context.
The list of backends that Mirage supports in the current version is already extremely broad. Storage and files: RAM, local disk, S3, R2, OCI, Supabase, Google Cloud Storage. Google productivity: Gmail, Google Drive, Google Docs, Google Sheets, Google Slides. Collaboration and communication: Slack, Discord, Telegram, Generic Email. Project management and code: GitHub, Linear, Notion, Trello. Databases: MongoDB, Redis, Postgres. Infrastructure: SSH and other backends coming soon. Every service is mounted as a folder in the same root.
An operation that copies an attachment from Gmail to S3 and then creates a document on Google Drive with the processing results is written as three sequential bash commands, with pipes connecting the results naturally. Without Mirage, the same operation would require completely different API calls for each of the three services, with manual management of data transfer between them.
Mirage is not an isolated tool. It was designed to integrate directly with the most used AI framework ecosystem: OpenAI Agents SDK, Vercel AI SDK, LangChain, Pydantic AI, CAMEL and OpenHands, Claude Code, and Codex. The SDKs are available in both Python and TypeScript. The filesystem can be embedded directly into FastAPI applications, Express, browser apps, or any asynchronous runtime without requiring a separate process.
In addition to unified backend access, Mirage offers some system features that become particularly valuable in complex agentic environments. Two-level caching: Mirage implements a two-layer cache system — a cache index and a file cache — that keeps recently read data locally. For agents that need to repeatedly access the same files or documents during task execution, this translates into significantly reduced latencies and fewer API calls to remote backends.
Snapshots and versioning: it's possible to take snapshots of the entire workspace at any given time, clone it, or roll back to a previous state with a single API call. For agentic workflows that make changes to live data — updating documents, moving files, writing to databases — this is a critical feature for operational safety. If an agent does something wrong, the rollback is immediate and complete.
Workspace isolation: every workspace in Mirage is an isolated environment with its own directory tree and mount configurations. This allows running multiple agents in parallel, each with its own view of the filesystem, without mutual interference.
The choice to use bash as the primary interface is not accidental and deserves reflection. Modern language models have been trained on huge amounts of text that include Unix documentation, bash tutorials, shell scripts, technical forums, and source code using command-line tools. This means that bash is likely the language in which LLMs are most fluent and confident — much more so than any proprietary SDK or custom API created after their training.
When an agent has to access a service via a specific SDK, it is operating in a context where it has fewer examples, fewer recognized patterns, and less intuition on how to handle edge cases. When it uses bash on a filesystem, it is operating in the context where its training was most dense and consistent. The quality of reasoning and the precision of operations improve, simply because the interface is the one the model knows best.
This insight — using the interface for which models are already optimized instead of building new ones — is one of the most solid design principles emerging in the AI agent ecosystem in 2026.
The project was released in May 2026 and is already one of the most discussed infrastructure tools in the AI ecosystem. With over 2,300 stars on GitHub within a few weeks of launch, Mirage immediately found an active community of developers who recognize the problem it solves — and who had likely already encountered it in their daily practice.
The Apache 2.0 license makes it freely usable even in commercial contexts, which lowers the barrier to adoption for companies that do not want dependencies on restrictive licenses. The fact that the team has already integrated support for major frameworks signals an ecosystem-oriented approach rather than the construction of an isolated technological island.
Mirage represents a shift in the approach to building agentic systems. Until today, the dominant trend was to build specific tools for each backend, define precise schemas for every operation, and manage integration complexity at the prompt level. It works, but it scales poorly and produces agents that become progressively more fragile as the number of integrated services increases.
Mirage's approach is the opposite: collapse the complexity into an infrastructure abstraction layer, outside of the agent's reasoning, and present the agent with a uniform and familiar interface. The agent stops being an API orchestrator and becomes a filesystem operator — a role for which language models are much better prepared than has been exploited so far.
For developers building AI agents intended to work in real corporate environments — where data fragmentation across dozens of different services is the norm — Mirage is a tool worth testing now, before it becomes the de facto standard everyone will be using in a year.