Mirage: il filesystem virtuale che risolve uno dei problemi più grandi degli agenti AI
C'è un problema che chiunque abbia mai provato a costruire un agente AI serio conosce bene. Non è il modello — i modelli oggi sono eccellenti. Non è il ragionamento — i LLM moderni ragionano in modo sorprendente. Il problema è l'accesso ai dati. Ogni servizio ha la sua API, ogni piattaforma ha il suo SDK, ogni backend richiede autenticazione diversa, chiamate diverse, gestione degli errori diversa, paginazione diversa. Un agente che deve lavorare con S3, Google Drive, Slack, Gmail, GitHub e un database Redis contemporaneamente finisce per portare in contesto una quantità enorme di complessità tecnica prima ancora di iniziare a fare qualcosa di utile. Mirage attacca questo problema alla radice, e lo fa con un'idea elegante nella sua semplicità: trasformare tutto in un filesystem.
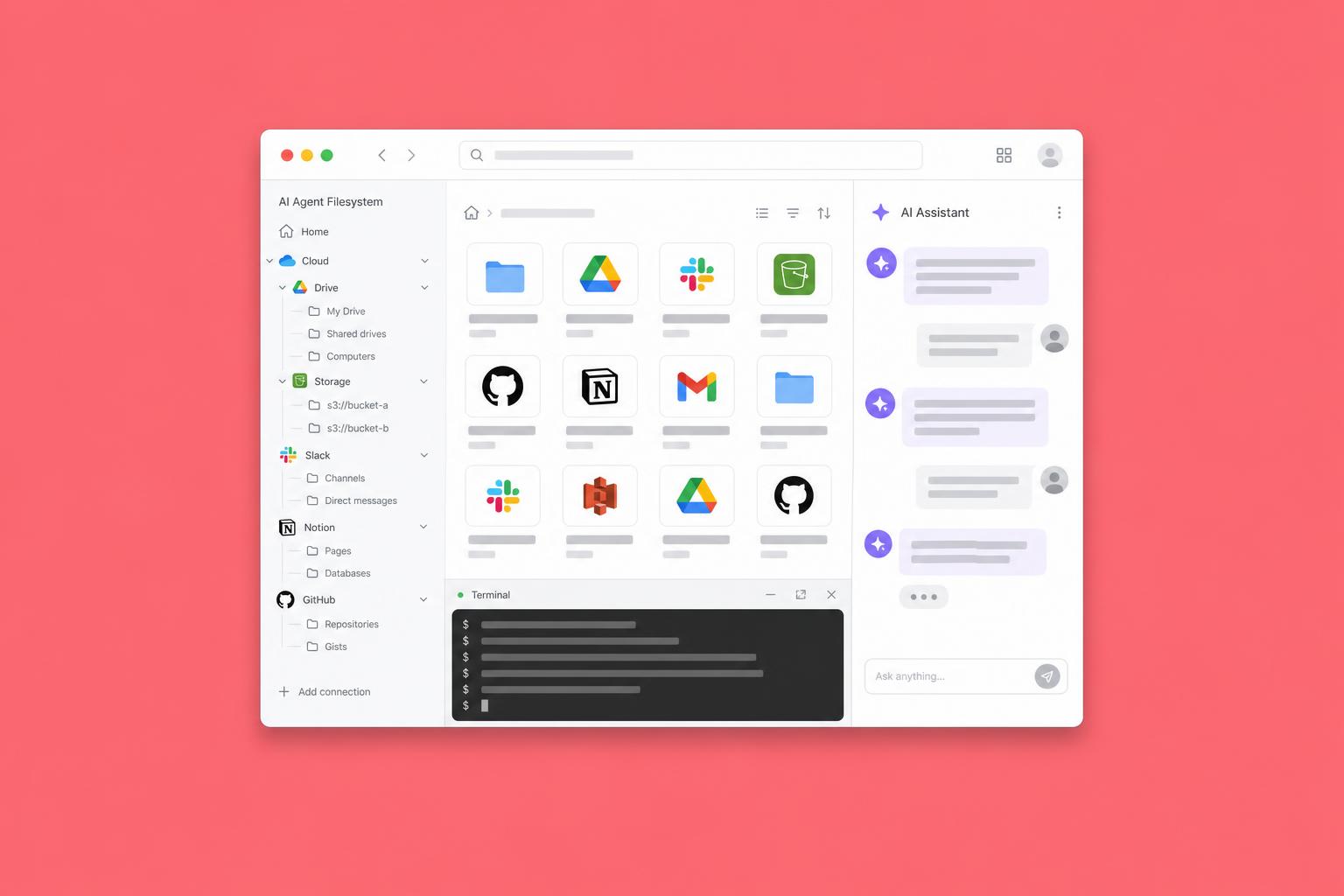
Mirage è un filesystem virtuale unificato per agenti AI, sviluppato da Strukto.ai e rilasciato come progetto open-source con licenza Apache 2.0. Il concetto centrale è quello che in Unix si chiama 'mount': invece di chiamare API diverse per accedere a servizi diversi, Mirage monta ogni servizio come una cartella all'interno di un unico albero di directory. S3 diventa /s3, Google Drive diventa /gdrive, Slack diventa /slack, Gmail diventa /gmail, GitHub diventa /github, Redis diventa /redis — e così via per tutti i servizi supportati.
Una volta montati, tutti questi backend si comportano come se fossero cartelle su un disco locale. L'agente AI può usare gli stessi comandi Unix che usa per qualsiasi filesystem: ls per listare i contenuti, cat per leggere un file, grep per cercare testo, cp per copiare dati da un servizio all'altro, head per leggere le prime righe di un documento. Non c'è nuovo vocabolario da imparare, non ci sono nuovi pattern da memorizzare. È bash. E i modelli linguistici sanno già usare bash meglio di qualsiasi altra interfaccia, perché è il sistema su cui sono stati addestrati più intensivamente.
Il team di Strukto.ai ha riscritto bash da zero in 1,1 milioni di righe di codice per farlo funzionare in questo contesto. Non si tratta di uno strato di compatibilità approssimativo: è un'implementazione completa che fa funzionare cat, grep, head e le pipe direttamente su file .parquet, .csv, .json e persino .wav, indipendentemente da dove quei file risiedano fisicamente.
Per capire perché Mirage è rilevante, vale la pena descrivere concretamente il problema che risolve. Un agente AI tipico in un contesto aziendale deve lavorare con dozzine di sistemi diversi. Deve leggere documenti da Google Drive, controllare email su Gmail, accedere a dati su S3, consultare ticket su Linear o Jira, leggere codice su GitHub, interrogare dati su MongoDB, usare cache su Redis, comunicare su Slack.
Senza un layer di astrazione, ogni singola di queste integrazioni richiede un SDK separato, una gestione dell'autenticazione separata, un set di tool separato da inserire nel prompt dell'agente, e una logica di gestione degli errori separata. Il risultato è quello che i developer chiamano 'tool-schema sprawl': il prompt dell'agente si riempie di decine di definizioni di tool, ognuna con i propri parametri, i propri casi limite, i propri pattern di utilizzo. Il modello deve tenere tutto questo in contesto mentre prova a ragionare sul task principale. È un carico cognitivo enorme che degrada direttamente la qualità del ragionamento.
Mirage collassa tutta questa complessità in un'unica astrazione: il filesystem. Invece di N SDK e M configurazioni MCP, l'agente vede una sola cosa — un albero di directory — e usa gli stessi cinque o sei comandi bash per accedere a qualsiasi backend. La complessità non scompare: viene spostata dentro Mirage, fuori dal contesto dell'agente.
La lista di backend che Mirage supporta nella versione attuale è già estremamente ampia. Storage e file: RAM, disco locale, S3, R2, OCI, Supabase, Google Cloud Storage. Produttività Google: Gmail, Google Drive, Google Docs, Google Sheets, Google Slides. Collaboration e comunicazione: Slack, Discord, Telegram, Email generico. Project management e codice: GitHub, Linear, Notion, Trello. Database: MongoDB, Redis, Postgres. Infrastruttura: SSH e altri backend in arrivo. Ogni servizio viene montato come una cartella nella stessa radice.
Un'operazione che copia un allegato da Gmail a S3 e poi crea un documento su Google Drive con i risultati dell'elaborazione si scrive come tre comandi bash sequenziali, con pipe che collegano i risultati in modo naturale. Senza Mirage, la stessa operazione richiederebbe chiamate API completamente diverse per ciascuno dei tre servizi, con gestione manuale del trasferimento dati tra di essi.
Mirage non è uno strumento isolato. È stato progettato per integrarsi direttamente con l'ecosistema di framework AI più usati: OpenAI Agents SDK, Vercel AI SDK, LangChain, Pydantic AI, CAMEL e OpenHands, Claude Code e Codex. Gli SDK sono disponibili sia in Python che in TypeScript. Il filesystem può essere incorporato direttamente dentro applicazioni FastAPI, Express, app browser o qualsiasi runtime asincrono, senza richiedere un processo separato.
Oltre all'accesso unificato ai backend, Mirage offre alcune funzionalità di sistema che diventano particolarmente preziose in ambienti agentici complessi. Cache a due livelli: Mirage implementa un sistema di cache con due strati — un indice cache e un file cache — che mantiene localmente i dati letti di recente. Per gli agenti che devono accedere ripetutamente agli stessi file o documenti durante l'esecuzione di un task, questo si traduce in latenze significativamente ridotte e in meno chiamate API verso i backend remoti.
Snapshot e versioning: è possibile fare snapshot dell'intero workspace in un dato momento, clonarlo o fare rollback a uno stato precedente con una singola chiamata API. Per i workflow agentici che effettuano modifiche a dati reali — aggiornano documenti, spostano file, scrivono su database — questa è una funzionalità critica per la sicurezza operativa. Se un agente fa qualcosa di sbagliato, il rollback è immediato e completo.
Workspace isolation: ogni workspace in Mirage è un ambiente isolato con il proprio albero di directory e le proprie configurazioni di mount. Questo permette di eseguire più agenti in parallelo, ciascuno con la propria vista sul filesystem, senza interferenze reciproche.
La scelta di usare bash come interfaccia primaria non è casuale e merita una riflessione. I modelli linguistici moderni sono stati addestrati su enormi quantità di testo che include documentazione Unix, tutorial bash, script shell, forum tecnici e codice sorgente che usa strumenti da riga di comando. Questo significa che bash è probabilmente il linguaggio in cui i LLM sono più fluenti e sicuri — molto di più di qualsiasi SDK proprietario o API personalizzata creata dopo il loro training.
Quando un agente deve accedere a un servizio tramite un SDK specifico, sta operando in un contesto in cui ha meno esempi, meno pattern riconosciuti, meno intuizione su come gestire i casi limite. Quando usa bash su un filesystem, sta operando nel contesto in cui il suo training è stato più denso e più coerente. La qualità del ragionamento e la precisione delle operazioni migliorano, semplicemente perché l'interfaccia è quella che il modello conosce meglio.
Questa intuizione — usare l'interfaccia per cui i modelli sono già ottimizzati invece di costruirne di nuove — è uno dei principi di design più solidi che stanno emergendo nell'ecosistema degli agenti AI nel 2026.
Il progetto è stato rilasciato a maggio 2026 ed è già uno degli strumenti infrastrutturali più discussi nell'ecosistema AI. Con oltre 2.300 stelle su GitHub in poche settimane dal lancio, Mirage ha trovato subito una community attiva di developer che riconoscono il problema che risolve — e che probabilmente lo avevano già incontrato nella propria pratica quotidiana.
La licenza Apache 2.0 lo rende utilizzabile liberamente anche in contesti commerciali, il che abbassa la barriera di adozione per aziende che non vogliono dipendenze da licenze restrittive. Il fatto che il team abbia già integrato il supporto per i principali framework segnala un approccio orientato all'ecosistema piuttosto che alla costruzione di un'isola tecnologica isolata.
Mirage rappresenta un cambio nell'approccio alla costruzione di sistemi agentici. Fino a oggi, la tendenza dominante era quella di costruire tool specifici per ogni backend, definire schema precisi per ogni operazione, e gestire la complessità dell'integrazione a livello di prompt. Funziona, ma scala male e produce agenti che diventano progressivamente più fragili all'aumentare del numero di servizi integrati.
L'approccio di Mirage è quello opposto: collassare la complessità in un layer di astrazione infrastrutturale, fuori dal ragionamento dell'agente, e presentare all'agente stesso un'interfaccia uniforme e familiare. L'agente smette di essere un orchestratore di API e diventa un operatore di filesystem — un ruolo per cui i modelli linguistici sono molto più preparati di quanto sia stato finora sfruttato.
Per i developer che stanno costruendo agenti AI destinati a lavorare in ambienti aziendali reali — dove la frammentazione dei dati tra decine di servizi diversi è la norma — Mirage è uno strumento che vale la pena testare ora, prima che diventi lo standard de facto che tutti useranno tra un anno.