Google Code Wiki: from GitHub repository to wiki with AI agent
There is a problem that every developer knows and no one likes to admit: documentation doesn't exist, it's incorrect, or it's so far behind the actual code that it's more misleading than no documentation at all. It's not the developers' fault — writing and maintaining documentation takes time, discipline, and a consistency that doesn't align well with the pace of a team that needs to deliver features. The result is that knowledge of how a codebase actually works lives in the heads of a few people, spreads slowly by osmosis, and is lost every time someone leaves the team. Google has decided to attack this problem at its root with Code Wiki, and the approach is worth understanding in depth.
Entering a codebase you didn't write yourself is, for many developers, one of the most frustrating experiences of daily work. Not because the code is necessarily poorly written — even well-written code takes time to be understood in its entirety — but because the higher level of abstraction is almost always missing: the reasons behind architectural choices, the relationships between modules, the repeating patterns, and the critical points where the system might break.
Reading code line by line tells you what it does. It doesn't tell you why it’s structured that way, what happens when you change this part, or where to find the logic that handles that edge case you're looking for. This contextual knowledge is precious, extremely rare to find documented, and very expensive to reconstruct from scratch every time.
The cost of this problem is measurable. Teams estimate that new developers take an average of weeks — sometimes months — before they are truly productive on a complex codebase. Every technology shift, every corporate acquisition, every open-source project with distributed contributors carries this same cost. Code Wiki targets exactly this point.
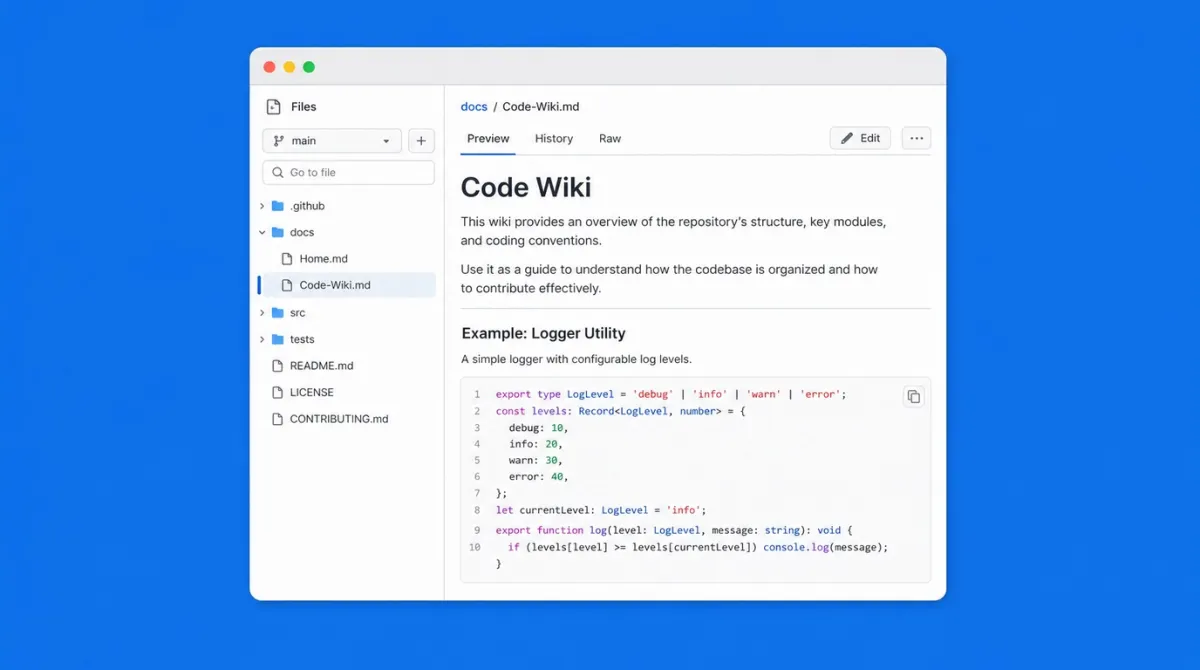
The user flow is intentionally simple: you connect a GitHub repository to Code Wiki, and the system does all the rest. In a few minutes, it generates an explorable and structured wiki of the entire codebase, which includes much more than manual documentation would typically include.
The generated wiki contains architectural diagrams showing how different components relate to each other, dependency graphs that make the project structure immediately comprehensible, explanations of main functions and modules with their role in the overall ecosystem, and annotations on recurring patterns and conventions adopted in the project.
All of this is generated by analyzing the actual source code, not by reading comments or README files that might be obsolete. The source of truth is the code itself, and the wiki reflects the current state of the repository, not the state of six months ago when someone had found the time to update the documentation.
The structured wiki is already useful on its own, but the element that transforms Code Wiki from an interesting tool into a potentially fundamental tool is the integrated AI agent, specifically trained on the connected repository.
The difference compared to pasting code into a generic model is substantial. A generic model has knowledge of the code you show it in the moment, but it lacks the context of the entire architecture, it doesn't know the specific conventions of that project, it doesn't know why certain choices were made, and it doesn't recognize patterns that repeat throughout the entire codebase. The Code Wiki agent, instead, is built with a semantic representation of the entire repository, which means its answers are contextually accurate in a way that no generic approach can replicate.
You can ask it where a specific feature is handled and it will point you to the exact file and function. You can ask what happens when you modify a certain parameter and it will describe the cascading dependencies. You can ask it to explain a part of the code as if you were new to the project, and it will do so with the level of detail you requested, without hallucinations or excessive simplifications.
Code Wiki is based on LLM Wiki, a knowledge base construction paradigm that represents a significant evolution over traditional RAG. It’s worth understanding the difference because it explains why the results are qualitatively superior.
In traditional RAG, documents are broken into chunks, converted into embeddings, and indexed. When a query arrives, the system retrieves the most similar chunks and inserts them into the model's context. It works, but it has a fundamental limit: chunks are isolated fragments that have lost their relationships with the rest of the document and other documents in the knowledge base.
LLM Wiki instead builds a structured representation of knowledge where relationships between concepts are explicit and navigable. Applied to a codebase, this means the system doesn’t just know 'this file contains this function,' but it knows that function is called by these other three modules, that it depends on this interface, and that it is part of this broader architectural pattern. When the agent answers a question, it draws on this relational structure — not on isolated chunks — and the result is a radically different quality of response.
The most immediate use cases are related to onboarding. A new developer joining a team can use Code Wiki to get a complete architectural overview of the project before even writing their first line of code. Instead of weeks of exploration and asking colleagues questions, they can build a structured understanding of the system in hours. The time savings and the reduced cognitive load on senior developers are measurable and significant.
Open-source project maintainers benefit in a different but equally concrete way. One of the most common problems in open-source projects with distributed contributors is the barrier to entry for those who want to contribute: understanding where to start, how the system works, and what conventions to follow. Code Wiki lowers this barrier drastically, potentially increasing the number of active contributors and the quality of their contributions.
Then there is the use case related to the analysis of third-party libraries. When evaluating the adoption of a new dependency, being able to explore its real architecture in a few minutes — not just marketing READMEs — radically changes the quality of technical decisions. You immediately understand how complex it actually is, what its weak points are, whether it is solidly maintained, or if it hides technical debt that will become a problem as soon as it's integrated into production.
Code Wiki doesn't magically solve the documentation problem: it shifts it. You no longer need to write and maintain it by hand, but you need to have code clean enough to be analyzed meaningfully. And you need to get used to a new way of working, where the primary source of truth for a codebase is no longer a poorly updated Confluence wiki, but an agent that knows the code better than anyone who wrote it. It is a cultural change even before a technological one — and probably one of the healthiest the industry has seen in a long time.