Google Code Wiki: da repository GitHub a wiki con agente AI
C'è un problema che tutti i developer conoscono e nessuno ama ammettere: la documentazione non esiste, è sbagliata, o è talmente indietro rispetto al codice reale da essere più fuorviante di nessuna documentazione. Non è colpa dei developer — scrivere e mantenere documentazione richiede tempo, disciplina e una costanza che mal si concilia con i ritmi di un team che deve consegnare feature. Il risultato è che la conoscenza su come funziona davvero una codebase vive nelle teste di poche persone, si trasmette lentamente per osmosi e si perde ogni volta che qualcuno lascia il team. Google ha deciso di attaccare questo problema alla radice con Code Wiki, e l'approccio vale la pena di essere capito in profondità.
Entrare in una codebase che non hai scritto tu è, per molti developer, una delle esperienze più frustranti del lavoro quotidiano. Non perché il codice sia necessariamente scritto male — anche codice ben scritto richiede tempo per essere compreso nella sua interezza — ma perché manca quasi sempre il livello di astrazione superiore: il perché delle scelte architetturali, le relazioni tra i moduli, i pattern che si ripetono, i punti critici dove il sistema può rompersi.
Leggere il codice riga per riga ti dice cosa fa. Non ti dice perché è strutturato così, cosa succede quando cambi questa parte, dove si trova la logica che gestisce quel caso limite che stai cercando. Questa conoscenza contestuale è preziosa, rarissima da trovare documentata e costosissima da ricostruire ogni volta da zero.
Il costo di questo problema è misurabile. I team stimano che i nuovi developer impieghino in media settimane — a volte mesi — prima di essere davvero produttivi su una codebase complessa. Ogni cambio di tecnologia, ogni acquisizione aziendale, ogni progetto open-source con contributor distribuiti porta con sé questo stesso costo. Code Wiki attacca esattamente questo punto.
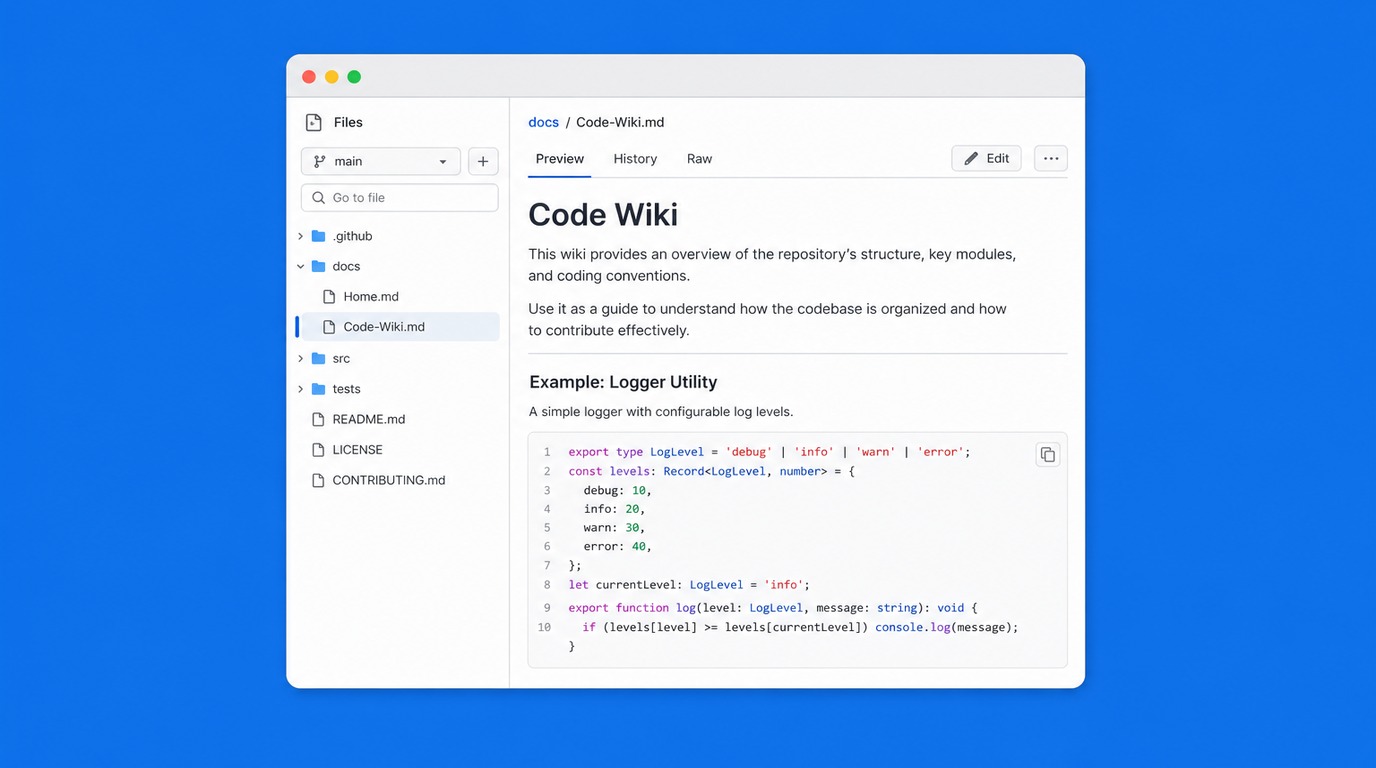
Il flusso di utilizzo è volutamente semplice: colleghi una repository GitHub a Code Wiki, e il sistema fa tutto il resto. In pochi minuti genera una wiki esplorabile e strutturata dell'intera codebase, che include molto più di quanto una documentazione scritta manualmente includerebbe tipicamente.
La wiki generata contiene schemi architetturali che mostrano come i diversi componenti si relazionano tra loro, grafici delle dipendenze che rendono visibile la struttura del progetto in modo immediatamente comprensibile, spiegazioni delle funzioni e dei moduli principali con il loro ruolo nell'ecosistema complessivo, e annotazioni sui pattern ricorrenti e sulle convenzioni adottate nel progetto.
Tutto questo viene generato analizzando il codice sorgente reale, non leggendo commenti o README che potrebbero essere obsoleti. La fonte di verità è il codice stesso, e la wiki riflette lo stato attuale della repository, non lo stato di sei mesi fa quando qualcuno aveva trovato il tempo di aggiornare la documentazione.
La wiki strutturata è già utile di per sé, ma l'elemento che trasforma Code Wiki da strumento interessante a strumento potenzialmente fondamentale è l'agente AI integrato, addestrato specificamente sulla repository collegata.
La differenza rispetto a incollare del codice in un modello generico è sostanziale. Un modello generico ha conoscenza del codice che gli mostri nel momento, ma non ha il contesto dell'intera architettura, non conosce le convenzioni specifiche di quel progetto, non sa perché certe scelte sono state fatte, non riconosce i pattern che si ripetono attraverso tutta la codebase. L'agente di Code Wiki invece è stato costruito con una rappresentazione semantica dell'intera repository, il che significa che le sue risposte sono contestualmente accurate in un modo che nessun approccio generico può replicare.
Puoi chiedergli dove viene gestita una funzionalità specifica e ti indicherà il file e la funzione esatti. Puoi chiedergli cosa succede quando modifichi un certo parametro e ti descriverà le dipendenze a cascata. Puoi chiedergli di spiegarti una parte del codice come se fossi nuovo al progetto, e lo farà con il livello di dettaglio che hai richiesto, senza invenzioni e senza semplificazioni eccessive.
Code Wiki si basa su LLM Wiki, un paradigma di costruzione delle knowledge base che rappresenta un'evoluzione significativa rispetto al RAG tradizionale. Vale la pena capire la differenza perché spiega perché i risultati sono qualitativamente superiori.
Nel RAG tradizionale, i documenti vengono spezzati in chunk, convertiti in embedding e indicizzati. Quando arriva una query, il sistema recupera i chunk più simili e li inserisce nel contesto del modello. Funziona, ma ha un limite fondamentale: i chunk sono frammenti isolati che hanno perso le relazioni con il resto del documento e con gli altri documenti della knowledge base.
LLM Wiki costruisce invece una rappresentazione strutturata della conoscenza in cui le relazioni tra i concetti sono esplicite e navigabili. Applicato a una codebase, questo significa che il sistema non sa solo "questo file contiene questa funzione", ma sa che quella funzione è chiamata da questi altri tre moduli, che dipende da questa interfaccia, che fa parte di questo pattern architetturale più ampio. Quando l'agente risponde a una domanda, attinge a questa struttura relazionale — non a chunk isolati — e il risultato è una qualità di risposta radicalmente diversa.
I casi d'uso più immediati sono quelli legati all'onboarding. Un nuovo developer che arriva in un team può usare Code Wiki per avere una panoramica architetturale completa del progetto prima ancora di scrivere la prima riga di codice. Invece di settimane di esplorazione e domande ai colleghi, può costruire una comprensione strutturata del sistema in ore. Il risparmio di tempo e il ridotto carico cognitivo sui senior developer sono misurabili e significativi.
I maintainer di progetti open-source beneficiano in modo diverso ma altrettanto concreto. Uno dei problemi più comuni nei progetti open-source con contributor distribuiti è la barriera d'ingresso per chi vuole contribuire: capire dove mettere mano, come funziona il sistema, quali sono le convenzioni da rispettare. Code Wiki abbassa questa barriera in modo drastico, potenzialmente aumentando il numero di contributor attivi e la qualità dei loro contributi.
C'è poi il caso d'uso legato all'analisi di librerie di terze parti. Quando si valuta l'adozione di una nuova dipendenza, poter esplorare in pochi minuti la sua architettura reale — non solo i README di marketing — cambia radicalmente la qualità delle decisioni tecniche. Si capisce subito quanto è complessa davvero, quali sono i suoi punti deboli, se è mantenuta in modo solido o se nasconde debito tecnico che diventerà un problema appena la si integra in produzione.
Code Wiki non risolve magicamente il problema della documentazione: lo sposta. Non serve più scriverla e mantenerla a mano, ma serve avere codice abbastanza pulito da poter essere analizzato in modo significativo. E serve abituarsi a un nuovo modo di lavorare, in cui la prima fonte di verità su una codebase non è più un wiki Confluence aggiornato male, ma un agente che conosce il codice meglio di chiunque lo abbia scritto. È un cambiamento culturale prima ancora che tecnologico — e probabilmente uno dei più sani che il settore abbia visto da molto tempo.