GPT-5.5 beats Opus 4.8? The truth after the tests
Every time a new OpenAI model is released, the community is divided. There are those who welcome it as a breakthrough and those who downplay it as an incremental update. The truth, almost always, lies in the middle — and it is only found by putting the models to the test on concrete tasks, not on official demos.
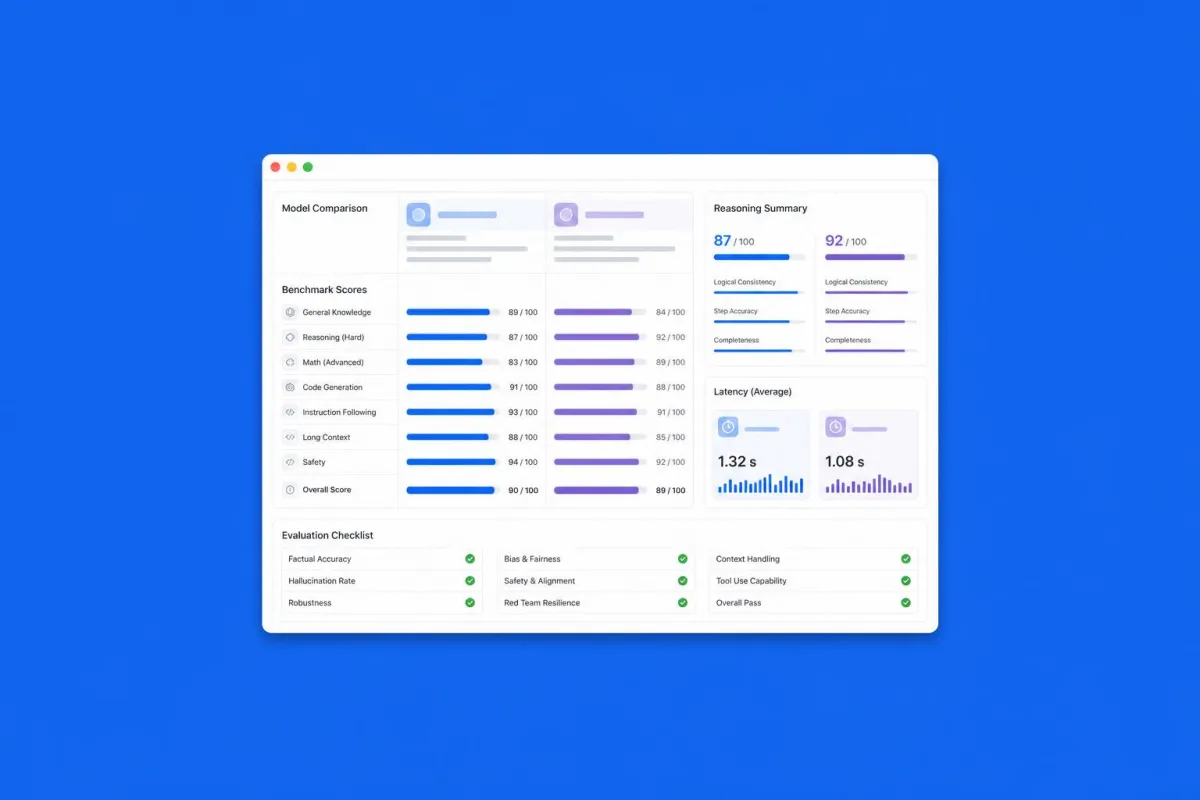
GPT-5.5 shows significant improvement across specific dimensions: coherence in long-form text, the ability to follow complex instructions with many simultaneous constraints, and the quality of code generation for less common languages. In these areas, the comparison with Claude Opus 4.8 becomes genuinely interesting.
Opus 4.8 remains superior on tasks that require autonomous multi-step reasoning: planning, executing, and self-correcting a sequence of actions. This is the type of capability that matters most in agentic contexts, where the model does not receive human feedback at every step.
The practical result is that the answer to the question 'which model is better' depends on the task. For content production, assisted coding, document synthesis, and managing complex conversations, the two models are closer than it seems. For autonomous and agentic workflows, Opus 4.8 maintains a clear edge.
The good news is that the general level is rising: in 2026, both models offer quality that just a few years ago was considered unreachable.
Related articles

Sam Altman says: “We're already in the singularity”. What it really means and why the most important question is a different one

Claude Opus 5: Anthropic launches the model that costs half of Fable 5 and marks the start of frontier AI commoditization
