GPT-5.5 batte Opus 4.8? La verità dopo i test
Ogni volta che esce un nuovo modello di OpenAI, la community si divide. C'è chi lo accoglie come una svolta e chi lo ridimensiona a un aggiornamento incrementale. La verità, quasi sempre, sta nel mezzo — e si trova solo mettendo i modelli alla prova su task concreti, non sulle demo ufficiali.
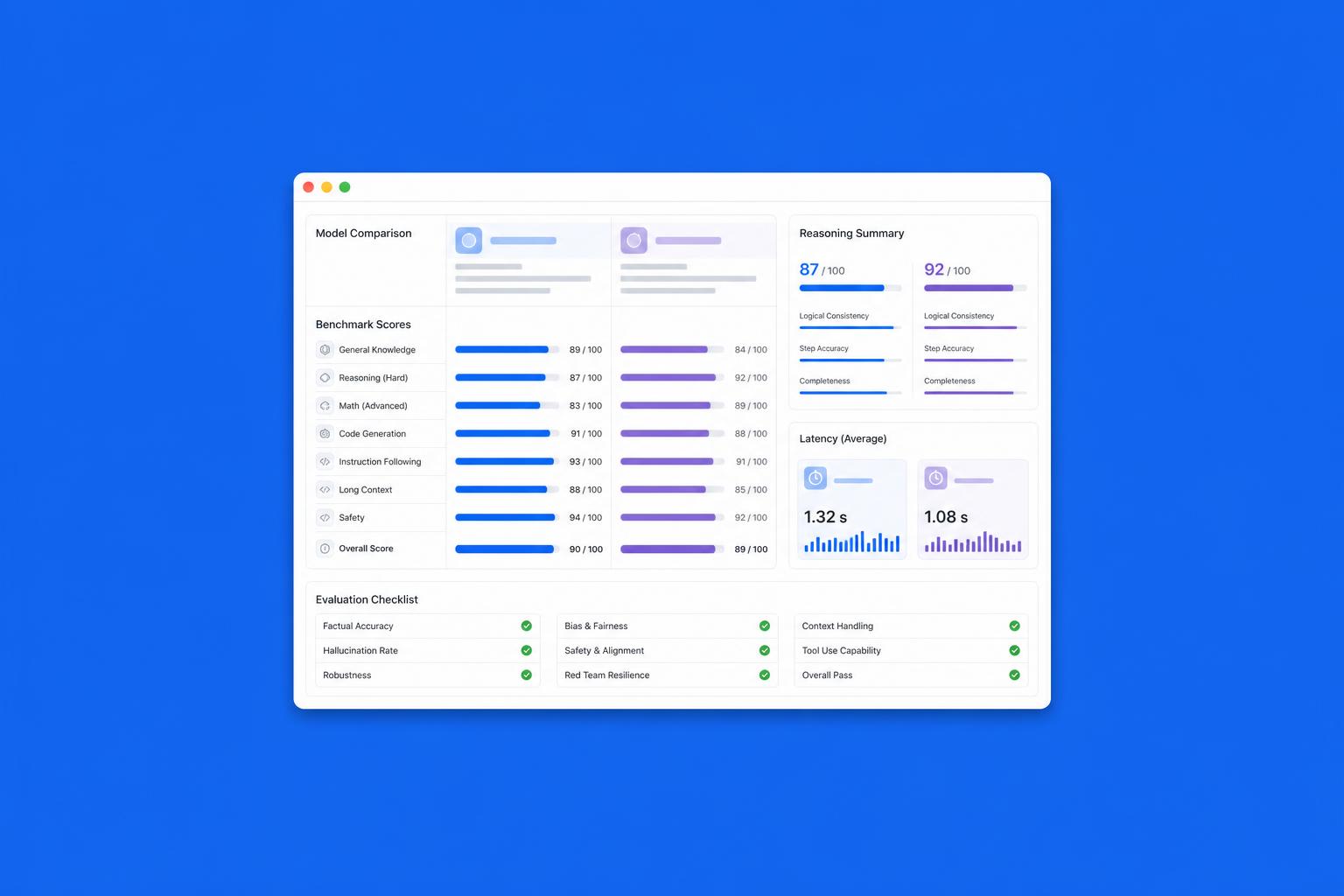
GPT-5.5 migliora in modo rilevante su alcune dimensioni specifiche: coerenza su testi lunghi, capacità di seguire istruzioni complesse con molti vincoli simultanei, qualità della generazione di codice su linguaggi meno diffusi. Su queste aree, il confronto con Claude Opus 4.8 diventa genuinamente interessante.
Opus 4.8 resta superiore sui task che richiedono ragionamento multi-step autonomo: pianificare, eseguire e correggere da soli una sequenza di azioni. È il tipo di capacità che conta di più in contesti agentici, dove il modello non riceve feedback umano ad ogni passo.
Il risultato pratico è che la risposta alla domanda 'quale modello è meglio' dipende dal task. Per produzione di contenuti, coding assistito, sintesi di documenti e gestione di conversazioni complesse, i due modelli sono più vicini di quanto sembri. Per workflow autonomi e agentici, Opus 4.8 mantiene un margine chiaro.
La buona notizia è che il livello generale si sta alzando: nel 2026 entrambi i modelli offrono qualità che fino a pochi anni fa era considerata irraggiungibile.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
