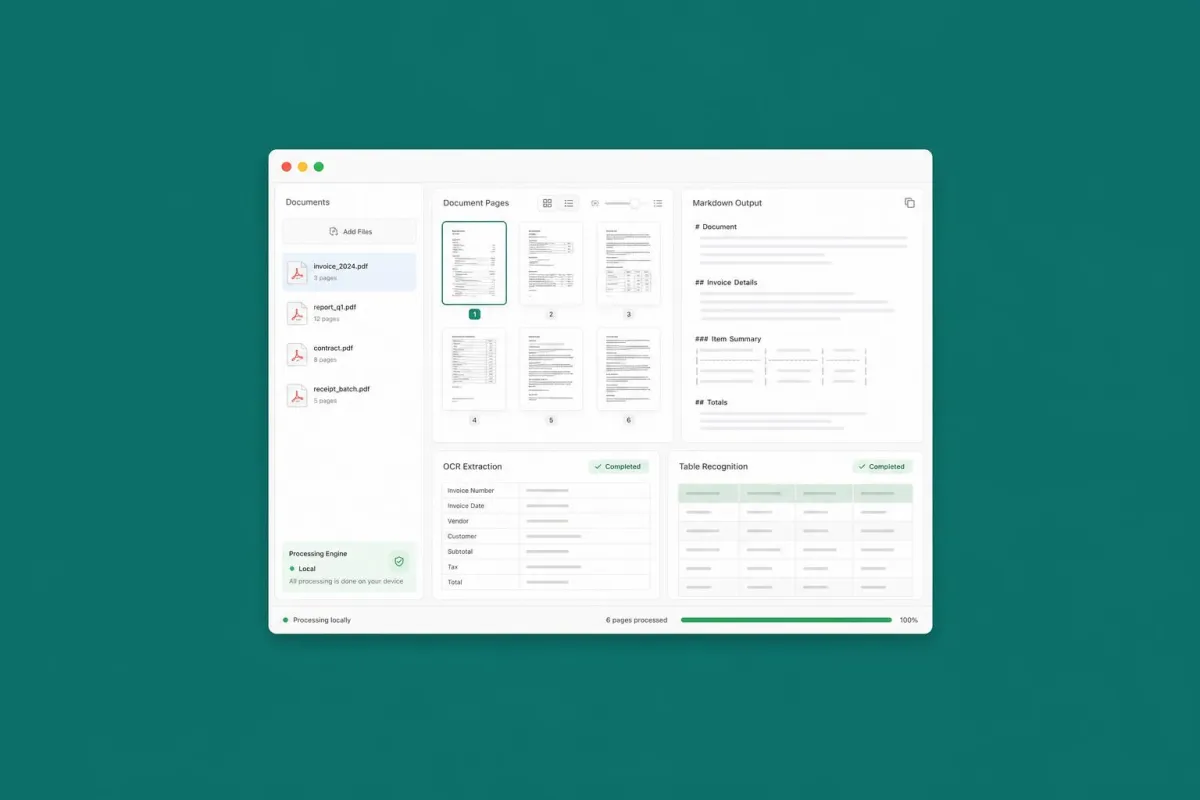
GLM-OCR Local: PDF to Markdown Without the Cloud
Extracting text from a PDF seems like a solved problem. Anyone who has worked with scanned documents, invoices, or reports with complex layouts knows that isn't the case. Traditional OCR pipelines work well on plain text but fail on tables, multiple columns, mathematical symbols, and nested headings.
GLM-OCR changes the approach: it doesn't just recognize characters, it understands the document structure and produces a Markdown output that maintains the original semantic hierarchy. Headings, tables, lists, bold text — everything is preserved in a format readable by both AI models and automation tools.
The point that makes this solution interesting for many teams is that it runs entirely locally. No data is sent to external servers, no API costs, no dependence on third parties subject to pricing or policy changes. For those working with contracts, medical dossiers, or financial statements, it's a substantial difference.
On an operational level, a GLM-OCR-based workflow can transform PDF archives into searchable knowledge bases, feed RAG pipelines with previously inaccessible documents, or automate data extraction from reports that used to require hours of manual work. Markdown is the ideal format precisely because it is spoken fluently by both humans and LLMs.
Related articles

Sam Altman says: “We're already in the singularity”. What it really means and why the most important question is a different one

Claude Opus 5: Anthropic launches the model that costs half of Fable 5 and marks the start of frontier AI commoditization
