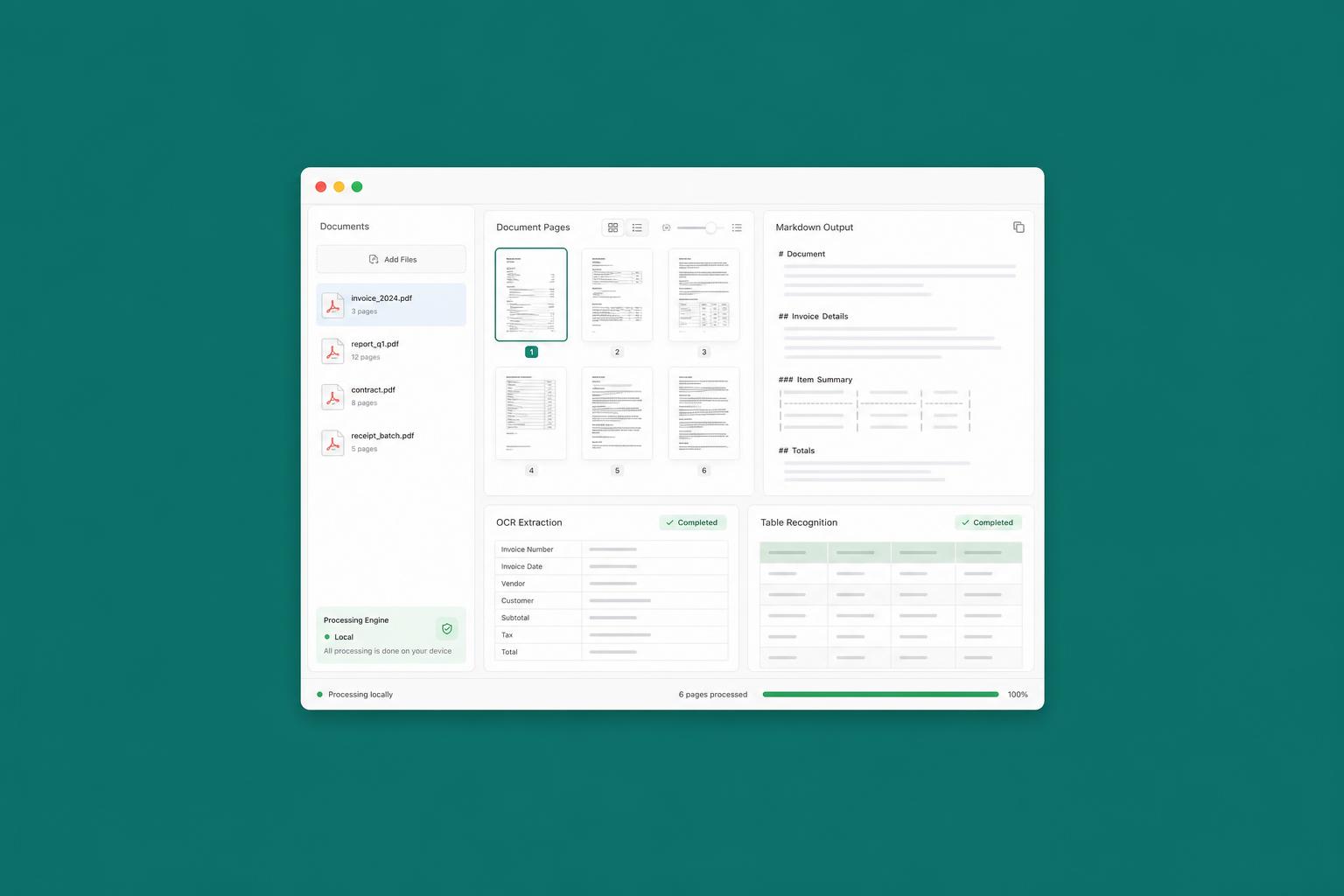
GLM-OCR in locale: PDF in Markdown senza cloud
Estrarre testo da un PDF sembra un problema risolto. Chiunque abbia lavorato con documenti scansionati, fatture o report con layout complessi sa che non è così. Le pipeline OCR tradizionali funzionano bene su testo semplice, ma cedono su tabelle, colonne multiple, simboli matematici e intestazioni nidificate.
GLM-OCR cambia l'approccio: non si limita a riconoscere i caratteri, ma capisce la struttura del documento e produce un output in Markdown che mantiene la gerarchia semantica originale. Intestazioni, tabelle, liste, grassetti — tutto preservato in un formato leggibile sia da modelli AI sia da strumenti di automazione.
Il punto che rende la soluzione interessante per molti team è che gira completamente in locale. Nessun dato inviato a server esterni, nessun costo per API, nessuna dipendenza da terze parti soggette a variazioni di pricing o policy. Per chi lavora con contratti, dossier medici o bilanci, è una differenza sostanziale.
Sul piano operativo, un workflow basato su GLM-OCR può trasformare archivi di PDF in knowledge base interrogabili, alimentare pipeline RAG con documenti prima inaccessibili o automatizzare l'estrazione dati da report che richiedevano ore di lavoro manuale. Il Markdown è il formato ideale proprio perché parlato fluentemente sia dagli umani sia dagli LLM.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
