DeepSeek V4 vs GPT-5.5 and Opus 4.8: Who Wins?
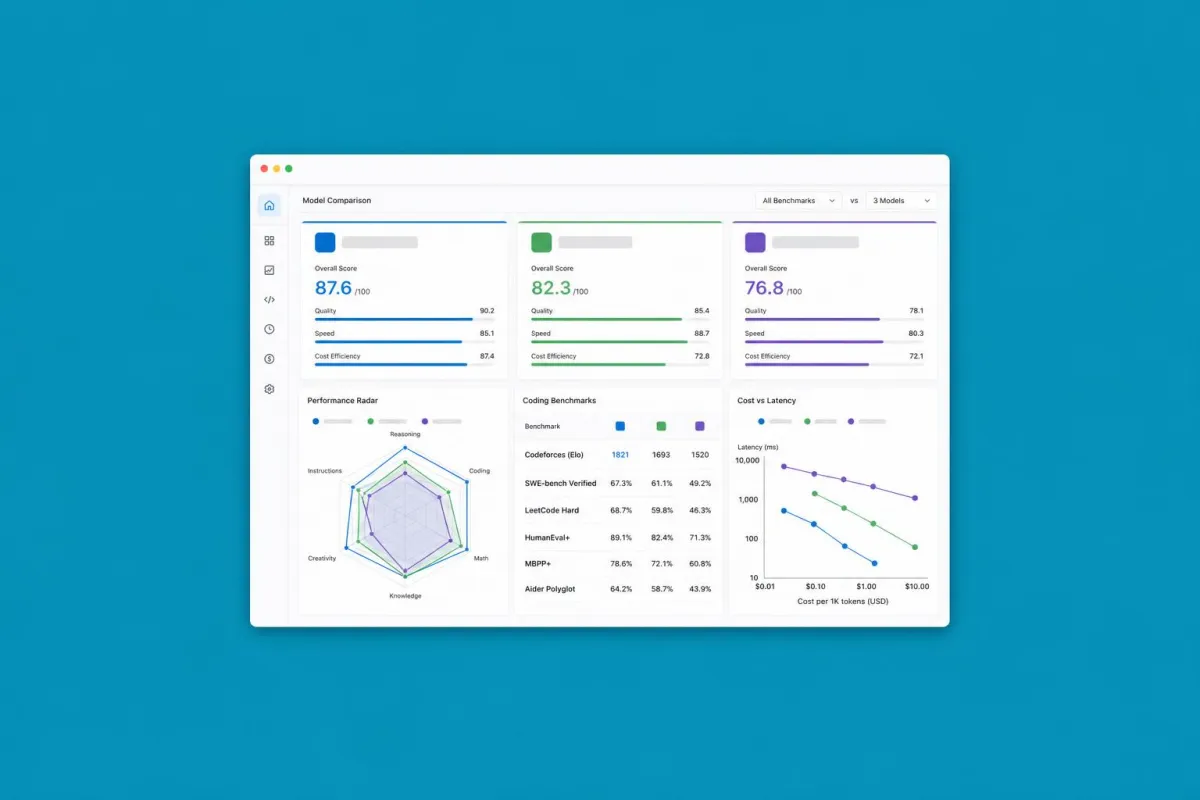
The AI model market is in a phase where releases are multiplying, and each one arrives with impressive benchmarks. DeepSeek V4 is no exception: top-tier numbers and the unique characteristic of being open-weight, meaning it can be deployed independently. But what happens when comparing it on real-world tasks with GPT-5.5 and Claude Opus 4.8?
The answer is more nuanced than press releases suggest. DeepSeek V4 shows excellent reasoning capabilities in mathematics and technical coding, remaining competitive with proprietary models on standardized benchmarks. GPT-5.5 maintains an advantage in general versatility and the quality of natural language in both Italian and English. Opus 4.8 remains the benchmark for deep reasoning and autonomous multi-step workflows.
What emerges from the tests goes beyond simple rankings: models behave differently depending on how they are prompted. Prompt quality, task structure, and the type of expected output enormously influence relative performance. A model that 'loses' on a generic benchmark can win decisively within its own application domain.
For those who must choose which model to adopt, the lesson is clear: there is no universal winner. There is only the most suitable model for your specific use case, budget, and desired level of infrastructure control.
Related articles

Sam Altman says: “We're already in the singularity”. What it really means and why the most important question is a different one

Claude Opus 5: Anthropic launches the model that costs half of Fable 5 and marks the start of frontier AI commoditization
