DeepSeek V4 vs GPT-5.5 e Opus 4.8: chi vince?
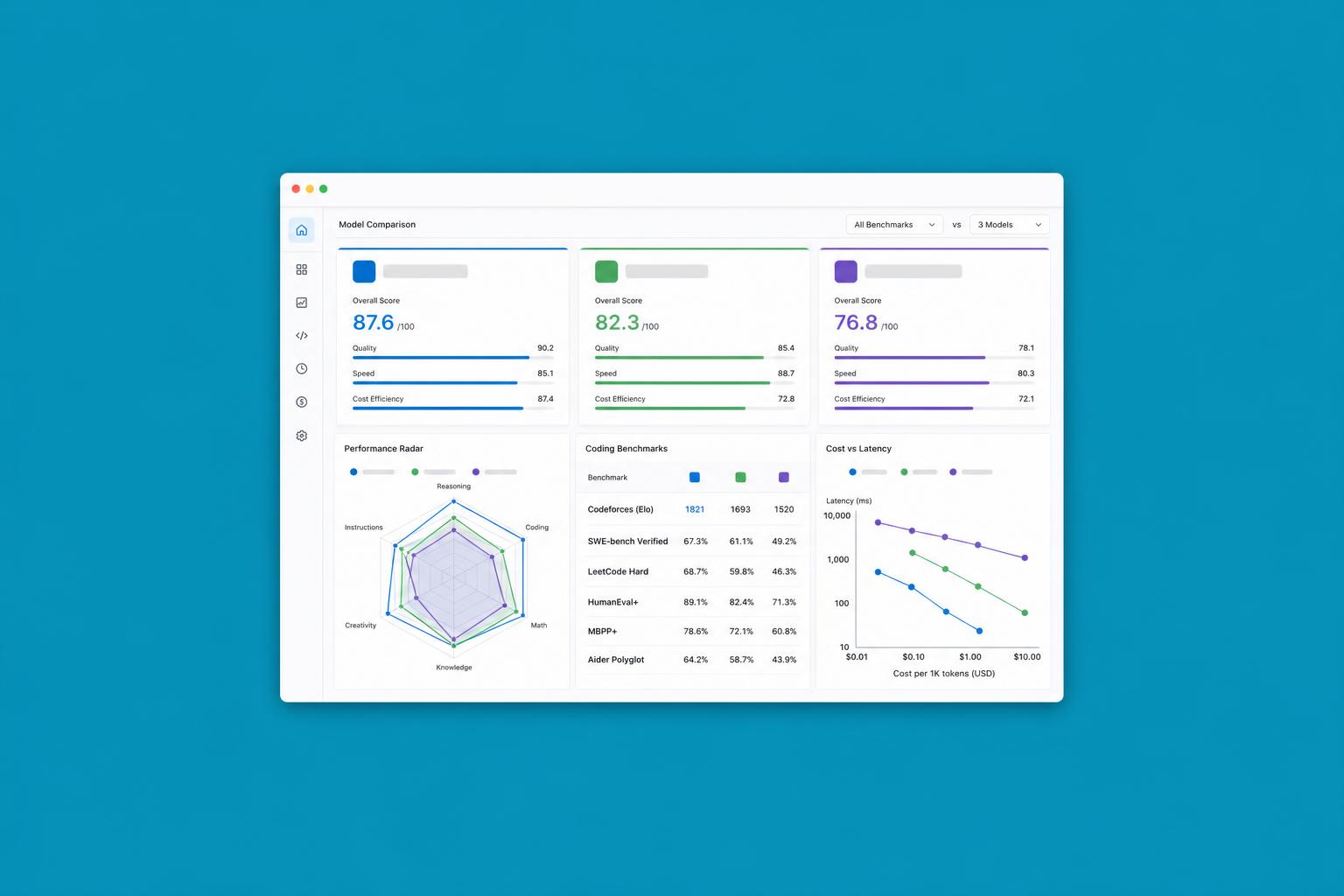
Il mercato dei modelli AI è in una fase in cui le release si moltiplicano e ognuna arriva con benchmark impressionanti. DeepSeek V4 non fa eccezione: numeri da top tier e la peculiarità di essere open-weight, quindi deployabile in autonomia. Ma cosa succede confrontandolo su task reali con GPT-5.5 e Claude Opus 4.8?
La risposta è più sfumata di quanto i comunicati stampa suggeriscano. DeepSeek V4 mostra eccellenti capacità di ragionamento su matematica e coding tecnico, competitivo con i modelli proprietari sui benchmark standardizzati. GPT-5.5 mantiene un vantaggio sulla versatilità generale e sulla qualità del linguaggio naturale in italiano e inglese. Opus 4.8 resta il riferimento per ragionamento profondo e workflow multi-step autonomi.
Quello che emerge dai test va oltre il ranking: i modelli si comportano diversamente a seconda di come vengono interrogati. La qualità del prompt, la struttura del task e il tipo di output atteso influenzano enormemente le prestazioni relative. Un modello che 'perde' su un benchmark generico può vincere nettamente sul proprio dominio applicativo.
Per chi deve scegliere quale modello adottare, la lezione è netta: non esiste un vincitore universale. Esiste il modello più adatto al proprio caso d'uso, al budget e al livello di controllo desiderato sull'infrastruttura.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
