What are AI agents: definition, operation, and examples in 2026
In 2026, 'AI agent' is probably the most overused expression in the tech sector. It is applied to slightly more evolved chatbots, automation workflows containing an LLM call, complex multi-step systems, and even simple writing copilots. The result is that entrepreneurs and corporate teams struggle to understand what they are actually buying and what they can truly expect. This article attempts to create order: what an AI agent is, what it isn't, how it really works, and where it makes sense to use it today.
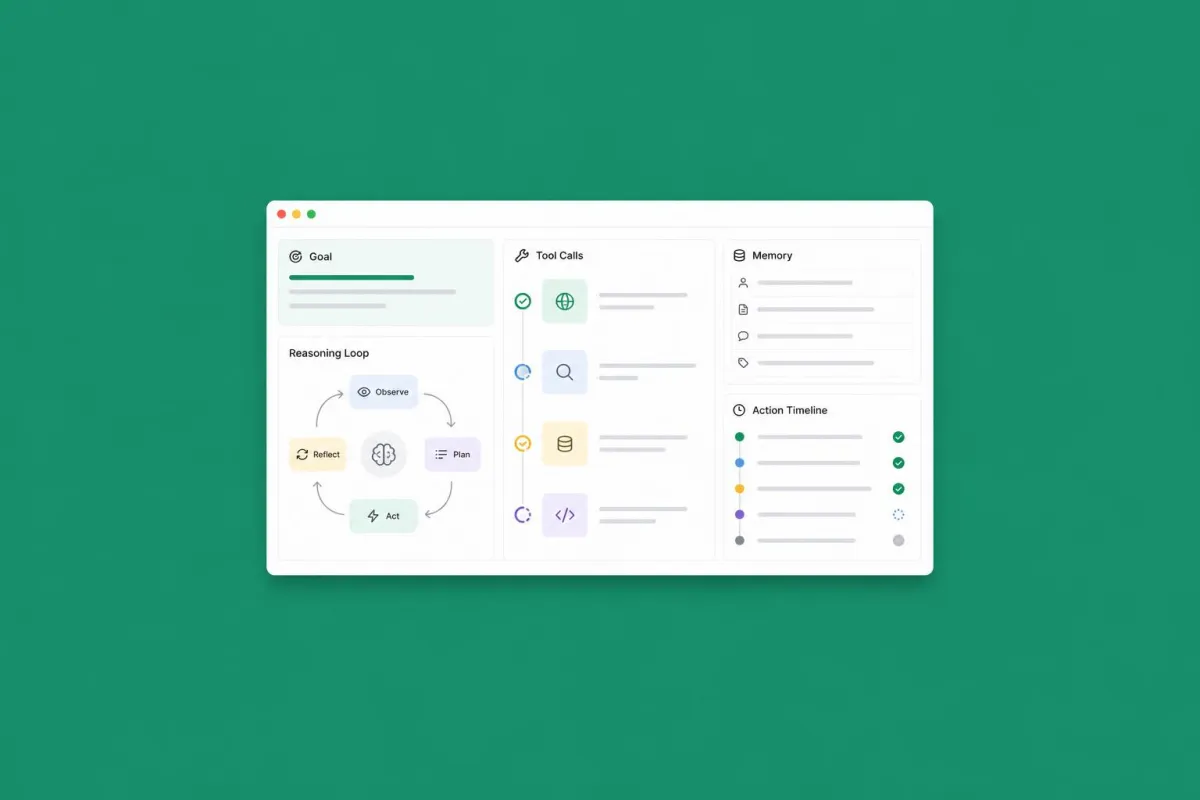
An AI agent is a system that, given a goal, autonomously decides which actions to take, executes them via external tools, observes the result, and adapts the next steps until it completes the task or declares it cannot do so. The operational definition rests on three words: goal, autonomy, action. If even one of these three is missing, you don't have an agent: you have a chatbot, a RAG pipeline, or a script.
A chatbot answers a question. A RAG pipeline searches for information in a knowledge base and summarizes it. An AI agent does something different: it receives a goal such as 'organize a call with client Rossi within the next five days in a slot where we are both free and send him the invitation' and from there it decides on its own to read the calendar, check the client's availability, propose a slot, generate the email, wait for confirmation, and create the event. No one told it in what order to do things — that is the piece that distinguishes it.
From a technical standpoint, an agent in 2026 is composed of four elements. The first is the reasoning model: typically Claude Opus 4.8, GPT-5.5, or Gemini 3.1 Pro, models capable of reliable multi-step reasoning and choosing which tools to call. The second is the tools, now almost always exposed via the MCP protocol (Model Context Protocol), which has become the de facto standard: every relevant SaaS — from GitHub to HubSpot, from Stripe to Notion — has an MCP server that allows the model to read and write data. The third is memory, which allows the agent to remember conversations, preferences, and facts between sessions. The fourth is the execution loop, the engine that decides when the task is finished, when it is worth retrying, and when to raise a hand and ask a human.
Understanding this anatomy is important because it helps to correctly read vendor promises. When a product presents itself as an 'AI agent' but does not expose real tools, does not maintain memory, and does not have an execution loop, nine times out of ten it is a well-packaged chatbot. It is not necessarily a bad thing — chatbots are useful — but pricing and expectations should be different.
A useful distinction in 2026 is that between reactive agents, orchestrated agents, and multi-agent systems. Reactive agents respond to a single trigger: 'an email arrives, classify it and route it'. They are simple, robust, and perfect for high-volume operational automations. Orchestrated agents manage tasks with multiple interdependent steps and conditional branching: most corporate use cases fall here. Multi-agent systems — a planner coordinating specialized sub-agents — are still at the frontier: spectacular in demos, but in production they are used only when the task is truly decomposable into independent sub-problems.
The use cases that generate real business value today are few, well-defined, and repeatable. First-level customer support, where the agent reads the knowledge base, checks the order status in the ERP, and resolves 80% of tickets without human intervention. Back-office operations: invoice reconciliation, contract classification, data extraction from technical PDFs. Sales operations: lead qualification, data enrichment on HubSpot or Salesforce, drafting commercial emails. Software development: agents like Claude Code and Cursor that read a repository, write code, test it, and open pull requests. Marketing: agents that monitor metrics, generate reports, and propose campaign variations.
What agents do not do well, and this is still true in 2026, is making decisions with a strong component of human judgment, managing new situations without precedents in their memory, or fully replacing senior professionals in high-responsibility activities. They work well as productivity multipliers for those who already know how to do the job, much less as complete substitutes.
On the infrastructure side, the adoption of MCP has changed the economics of the sector. Until 2024, connecting a model to one's systems required custom integrations, each with its own authentication, error schema, and rate limits. Today, a team that wants an agent connected to Slack, Gmail, Stripe, and Notion already has four official MCP servers ready. This has drastically lowered the entry cost and explains why in 2026 even companies with 10–20 people are starting to have agents in production, not just enterprises.
Regarding models, the snapshot of May 2026 is that of a stabilizing market: Anthropic leads on long reasoning quality (Opus 4.8), OpenAI on real-time multimodality (GPT-5.5 voice, GPT-5.5 vision), Google on massive contexts (Gemini 3.1 Pro with over 1 million tokens), and DeepSeek and Gemma on efficiency for high-volume tasks. Choosing the right model for an agent is not a matter of fandom: it depends on the type of task, the volume, and the budget per execution.
For those considering introducing AI agents in the company, the right question is not 'is this model smart enough'. Almost always, it is. The question is: do I have a repetitive, well-defined task with structured data that the model can access and a verifiable output? If the answer is yes, the AI agent in 2026 is a mature choice, with measurable ROI and short implementation times. If the answer is no — if the task is ambiguous, if the data is only in people's heads, if success is subjective — then an AI agent is premature, and investing first in data and processes is worth more than investing in models.
The most honest way to describe AI agents today is this: they are neither the total revolution promised in 2023 nor the hype destined to deflate. They are a new category of software that becomes useful when the problem is well-posed, the tools are well-exposed, and success is well-measured. Everything else — parameter counts, benchmarks, viral demos — is secondary to this verification.
Related articles

Paperclip: the open source framework that lets you build a company of autonomous AI agents, with 74,000 stars on GitHub

How to build an AI agent for your business: a practical SMB guide with Claude, n8n and Supabase