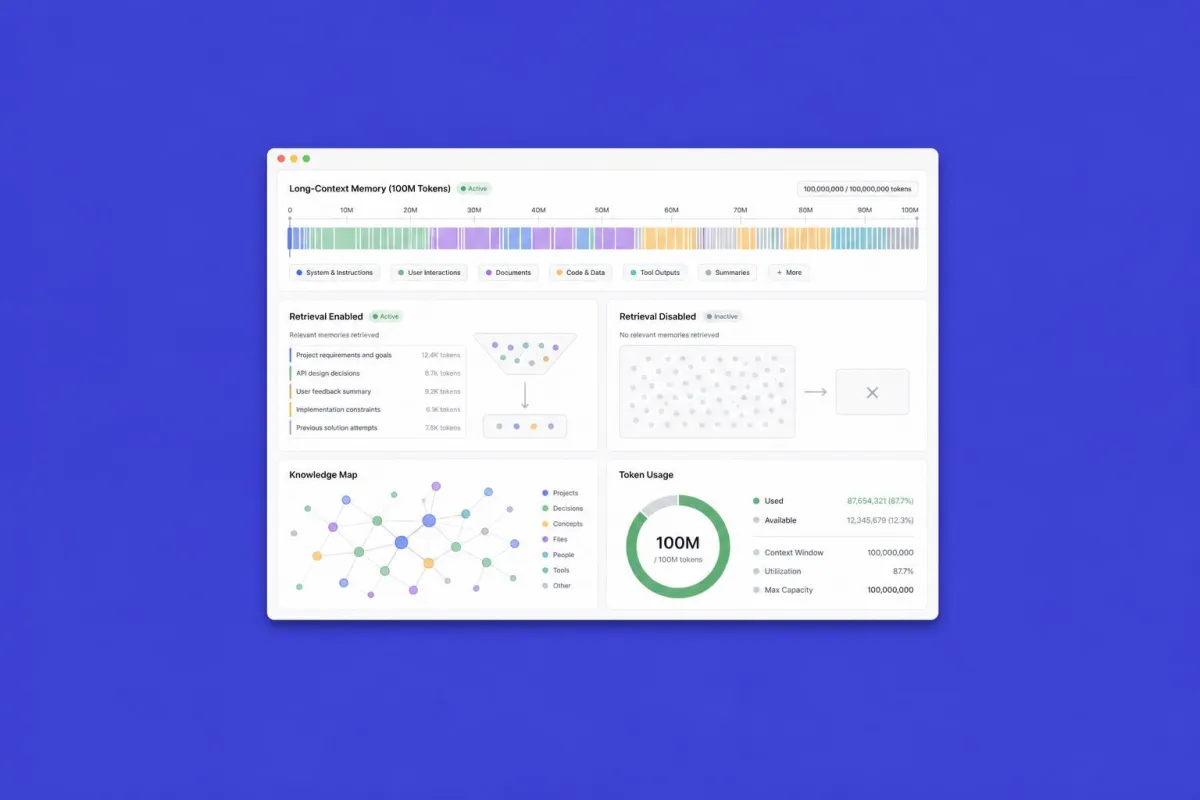
AI with 100M token memory: Is this the end of RAG?
For years, RAG — Retrieval-Augmented Generation — has been the standard answer to the knowledge problem in AI systems: if the model doesn't know something, we retrieve it from the database and inject it into the context. A robust architecture, widely adopted and well understood. But something is changing, and the direction is surprising: 100 million token context windows.
When a model can hold an amount of text equivalent to tens of thousands of pages in its head, the question arises naturally: does it still make sense to build retrieval pipelines, or are we entering an era where the model's memory becomes the architecture?
The answer is not binary. Huge windows do not automatically eliminate RAG: the computational cost of processing 100M tokens for every request is still high, the quality of attention degrades on distant information, and well-designed RAG systems remain cheaper and more precise for very large corporate knowledge bases.
The change, however, is real. For applications requiring narrative consistency over long documents, analysis of entire codebases, or conversations with very extensive history, a large context window can eliminate entire layers of architectural complexity.
For those designing AI systems today, the practical question is: which use cases are becoming simpler with massive context windows, and where does RAG remain the smart choice? Answering correctly means avoiding both over-engineering and over-simplification.
Related articles

Sam Altman says: “We're already in the singularity”. What it really means and why the most important question is a different one

Claude Opus 5: Anthropic launches the model that costs half of Fable 5 and marks the start of frontier AI commoditization
