AI con 100M token di memoria: è la fine del RAG?
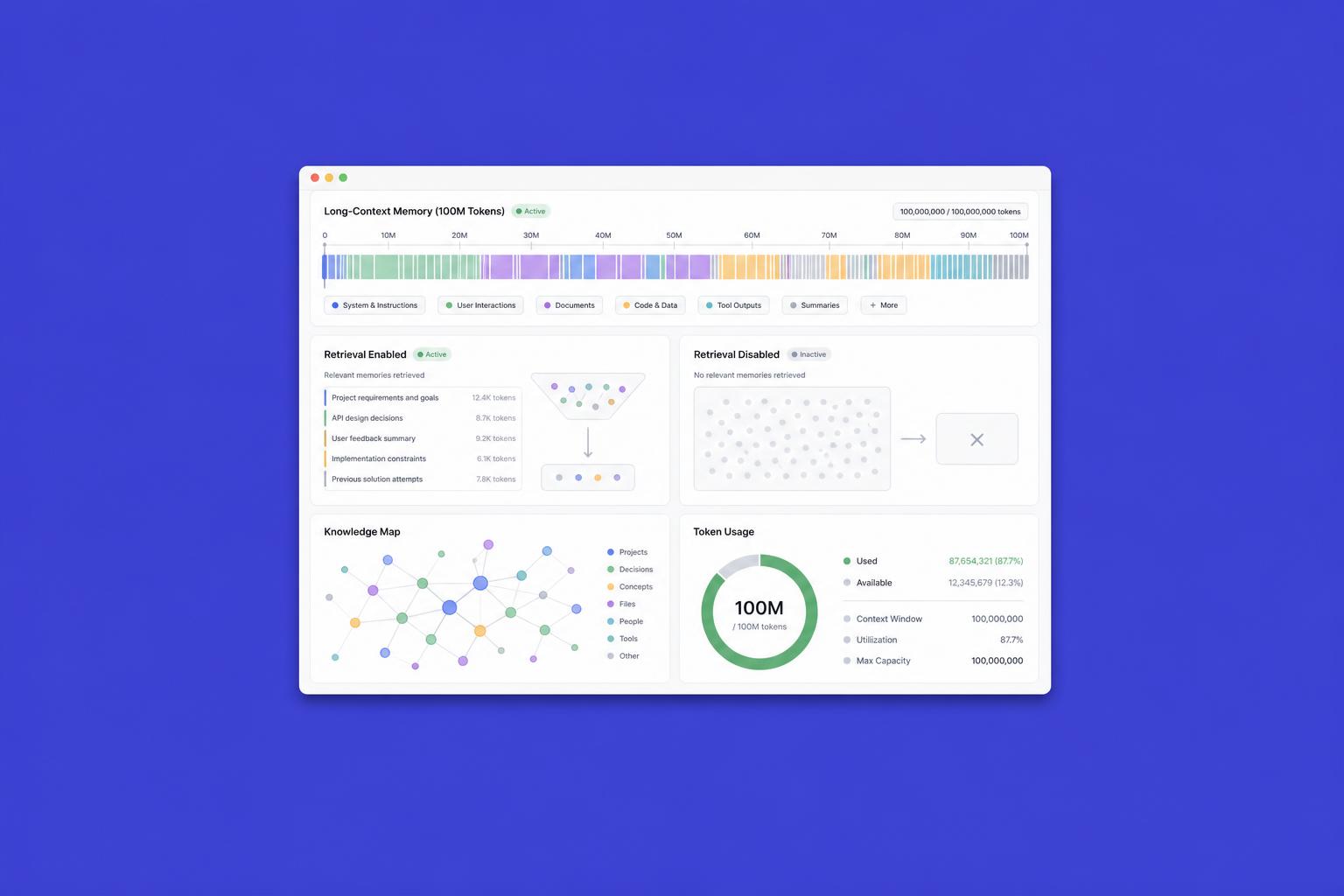
Per anni il RAG — Retrieval-Augmented Generation — è stato la risposta standard al problema della conoscenza nei sistemi AI: il modello non sa qualcosa, lo recuperiamo dal database e lo iniettiamo nel contesto. Un'architettura robusta, ampiamente adottata e ben compresa. Ma qualcosa sta cambiando, e la direzione è sorprendente: finestre di contesto da 100 milioni di token.
Quando un modello può tenere in testa una quantità di testo equivalente a decine di migliaia di pagine, la domanda nasce spontanea: ha ancora senso costruire pipeline di retrieval, o stiamo entrando in un'era in cui la memoria del modello diventa l'architettura?
La risposta non è binaria. Le finestre enormi non eliminano automaticamente il RAG: il costo computazionale di processare 100M token ad ogni richiesta è ancora alto, la qualità dell'attenzione degrada sulle informazioni distanti e i sistemi RAG ben progettati restano più economici e precisi su knowledge base aziendali molto grandi.
Il cambiamento però è reale. Per applicazioni che richiedono coerenza narrativa su documenti lunghi, analisi di codebase intere o conversazioni con storico molto esteso, una grande finestra di contesto può eliminare interi strati di complessità architetturale.
Per chi progetta sistemi AI oggi, la domanda pratica è: quali use case stanno diventando più semplici con context window enormi e dove invece il RAG resta la scelta intelligente? Rispondere bene significa evitare sia l'over-engineering sia la semplificazione eccessiva.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
