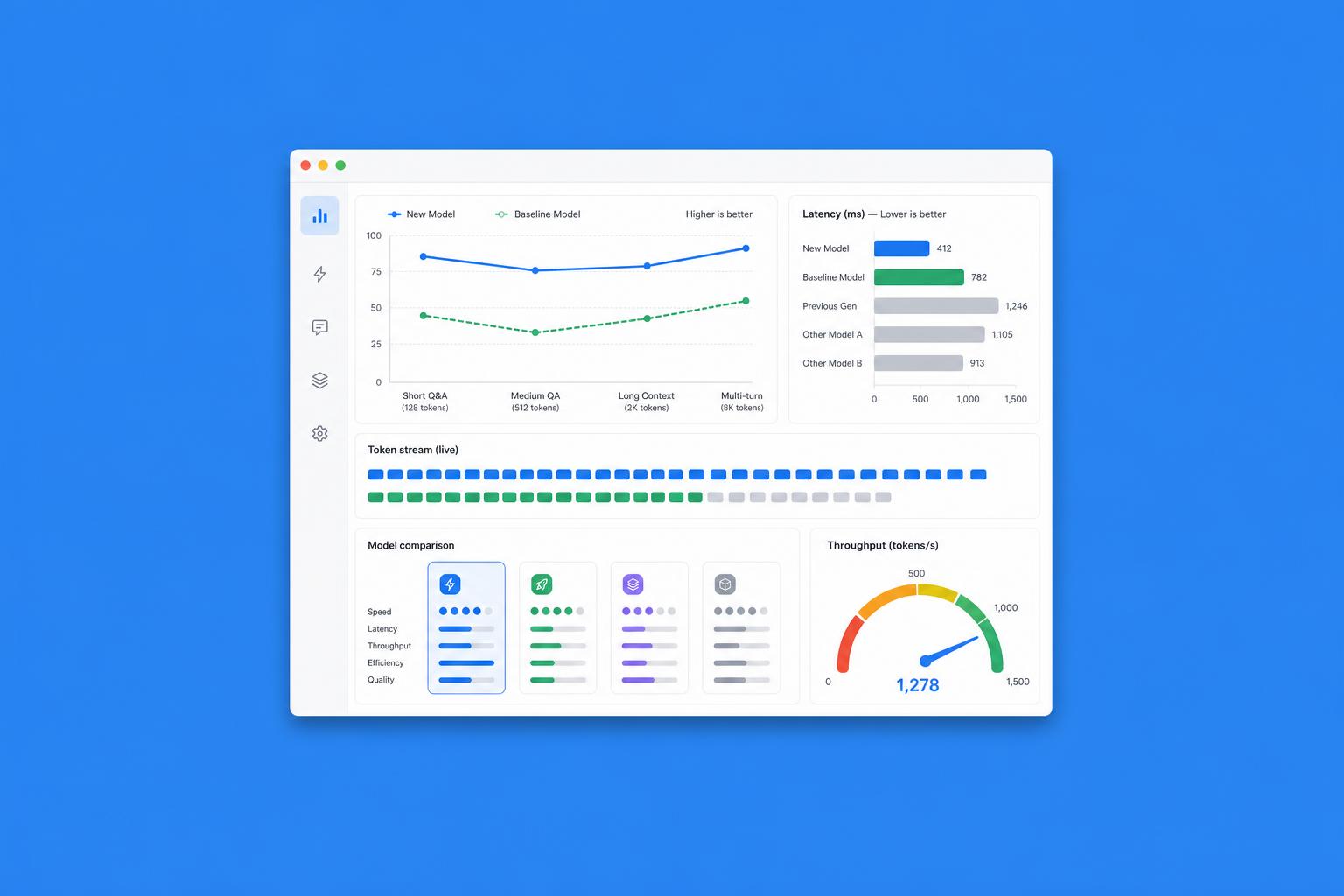
Gemma 4 diventa 3x più veloce grazie a MTP
La velocità di inferenza è uno dei colli di bottiglia più sottovalutati nell'adozione pratica dei modelli AI. Quando si parla di qualità, l'attenzione va quasi sempre ai benchmark di ragionamento, alla qualità del codice generato o alla precisione nelle risposte. Ma in produzione la latenza conta quanto — se non di più — della qualità assoluta. Un modello eccellente che impiega 10 secondi a rispondere è meno utile di un modello molto buono che risponde in 2. Google lo sa, e l'aggiornamento a Gemma 4 con supporto MTP ne è la dimostrazione concreta.
MTP sta per Multi-Token Prediction, una tecnica di inferenza che rompe il paradigma classico della generazione autoregressiva. Nei modelli linguistici tradizionali ogni token viene generato uno alla volta, in sequenza: il modello produce un output, lo reinserisce come input, genera il successivo, e così via. È un processo intrinsecamente seriale, e questa serialità è il limite fondamentale della velocità di generazione.
MTP affronta il limite in modo elegante: invece di predire un solo token per volta, il modello impara a predire più token contemporaneamente, in parallelo. Non si tratta di speculazione casuale — il modello usa la propria comprensione del contesto per anticipare con alta probabilità i token successivi, verificarli e accettarli in blocco quando corretti. Il risultato è un aumento drastico del throughput senza degradazione misurabile nella qualità dell'output. Applicato a Gemma 4, l'incremento dichiarato è di tre volte rispetto alla versione precedente: nella pratica significa passare da latenze adatte principalmente a task batch o offline a latenze compatibili con applicazioni interattive real-time.
Gemma è la famiglia di modelli open-weight di Google: disponibili liberamente, deployabili in locale o su qualsiasi infrastruttura cloud, senza dipendenza dalle API di Google. Questo li rende particolarmente attrattivi per aziende con requisiti di privacy, team con budget limitati per API esterne e sviluppatori che vogliono controllo completo sull'infrastruttura. Il limite storico di Gemma rispetto ai modelli proprietari di punta era proprio la velocità: ottima qualità per la dimensione del modello, ma inferenza più lenta di quanto accettabile in certi contesti applicativi. Con MTP questo gap si riduce in modo significativo.
Le applicazioni che beneficiano di più di questo aggiornamento sono quelle dove la latenza è un parametro critico: assistenti conversazionali in tempo reale, sistemi di completamento testuale, agenti AI che devono elaborare e rispondere rapidamente a input sequenziali, e pipeline di processing che elaborano grandi volumi di documenti in batch. In tutti questi scenari triplicare la velocità di inferenza non è un miglioramento incrementale: è un cambio di categoria.
L'aggiornamento va letto anche in un contesto strategico più ampio. Google sta investendo in modo crescente nella distribuzione open-weight dei propri modelli, e Gemma è il veicolo principale di questa strategia. Rendere Gemma 4 significativamente più veloce aumenta la sua competitività rispetto ad alternative come Llama, Mistral e GLM — tutti modelli che si contendono lo stesso spazio di adozione tra sviluppatori e aziende che vogliono controllo sull'infrastruttura. Più team adottano Gemma come base per le proprie applicazioni, più cresce l'ecosistema di strumenti, integrazioni e competenze intorno ai modelli Google. L'open-source, in questo senso, non è filantropia tecnologica: è una strategia di distribuzione che costruisce dipendenza dall'ecosistema nel tempo.
MTP non è una tecnica esclusiva di Google: altri laboratori stanno esplorando approcci simili per accelerare l'inferenza senza aumentare il costo computazionale del training. Quello che rende rilevante l'implementazione su Gemma 4 è la scala di adozione che potrebbe raggiungere: un modello open-weight veloce, di qualità elevata e liberamente deployabile ha tutte le caratteristiche per diventare un nuovo standard di riferimento per applicazioni AI in produzione. Per chi sta valutando quale modello adottare come base per nuovi progetti, Gemma 4 con MTP entra ora concretamente nella lista delle opzioni da testare — non solo per la qualità, ma perché la velocità di inferenza è finalmente all'altezza delle esigenze applicative reali.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
