Come creare un agente AI nel 2026: guida pratica end-to-end
Costruire un agente AI nel 2026 non assomiglia più al lavoro sperimentale di due anni fa. Le primitive sono mature, gli SDK sono stabili e il protocollo MCP è ormai lo standard de facto per collegare modelli e strumenti. Quello che fino al 2024 richiedeva settimane di prompt engineering oggi si costruisce in poche ore, a patto di partire dalle scelte giuste e di non confondere un agente con un semplice chatbot dotato di funzioni.
La prima domanda non è 'quale framework uso' ma 'qual è il job che l'agente deve chiudere'. Un agente è utile quando deve prendere una decisione, scegliere quali strumenti chiamare in che ordine e adattarsi al risultato delle azioni precedenti. Se il flusso è deterministico — input, trasformazione, output — non serve un agente: serve uno script con una chiamata LLM dentro. Confondere i due livelli è la causa numero uno di progetti che bruciano token senza produrre valore.
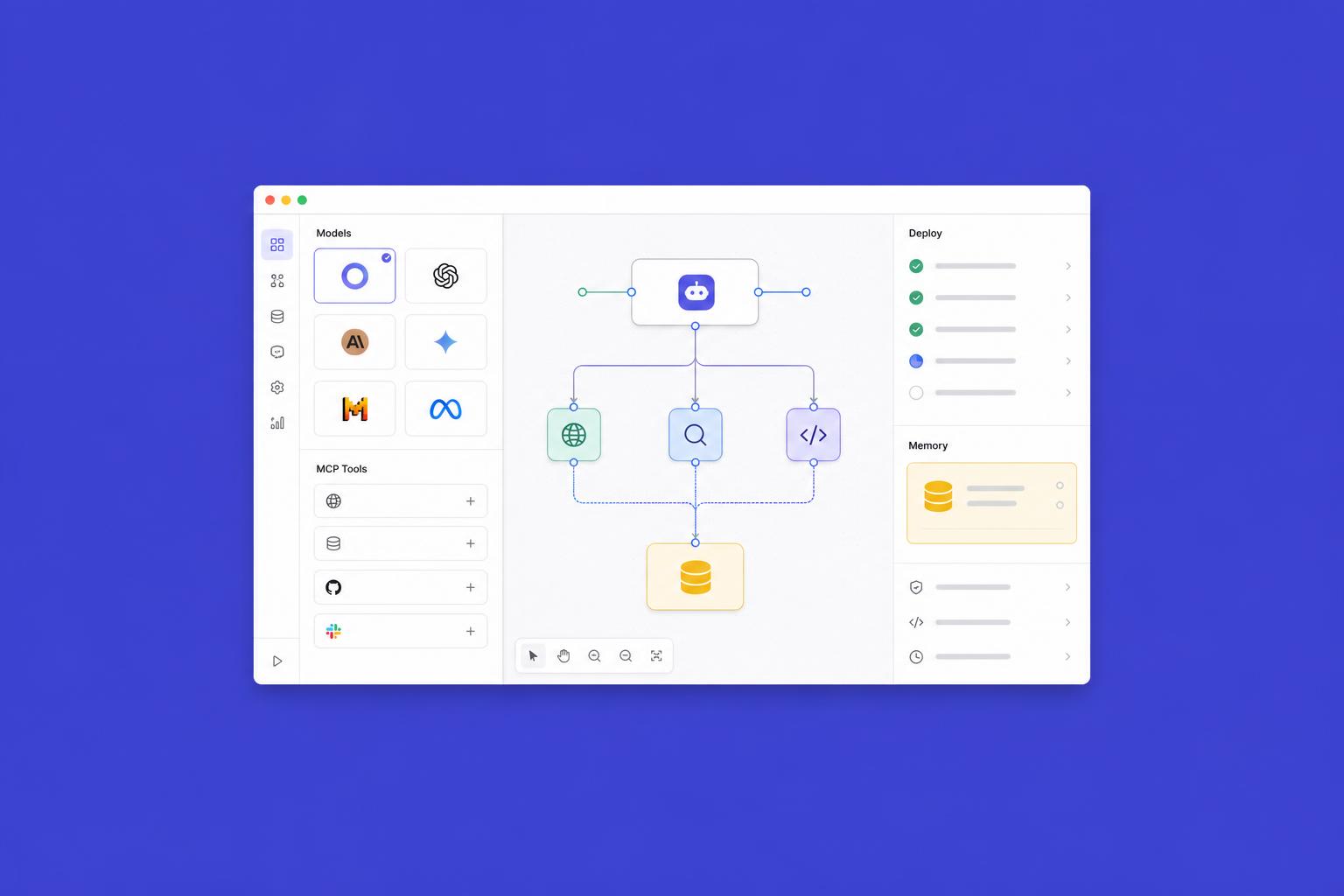
Una volta chiarito il job, la scelta del modello segue quasi automaticamente. A maggio 2026 il quadro è abbastanza stabile: Claude Opus 4.8 resta lo standard per agenti che devono scrivere codice, leggere repository grandi e gestire piani lunghi con molte revisioni. GPT-5.5 è la prima scelta per agenti conversazionali multimodali, vocali in tempo reale o con forte componente vision. Gemini 3.1 Pro vince quando servono contesti enormi (oltre 1 milione di token) o quando l'agente deve ragionare su documenti video lunghi. Per task ad alto volume e basso margine — classificazione, smistamento, estrazione — Gemma 4 MTP e GPT-5.5 mini abbattono il costo unitario di un ordine di grandezza.
La differenza tra un agente e uno script LLM è che l'agente sa usare strumenti. Nel 2026 questo significa una cosa precisa: esporre i tool tramite MCP (Model Context Protocol). MCP è arrivato a v1 ed è supportato nativamente da Anthropic, OpenAI e Google, oltre che da n8n, Zapier, GitHub, Notion e dalla quasi totalità dei SaaS rilevanti. Scrivere connettori custom oggi ha senso solo per logiche proprietarie: per Slack, Gmail, HubSpot, Stripe, Supabase e simili esistono già server MCP ufficiali o ben mantenuti, e usarli ti risparmia mesi di manutenzione.
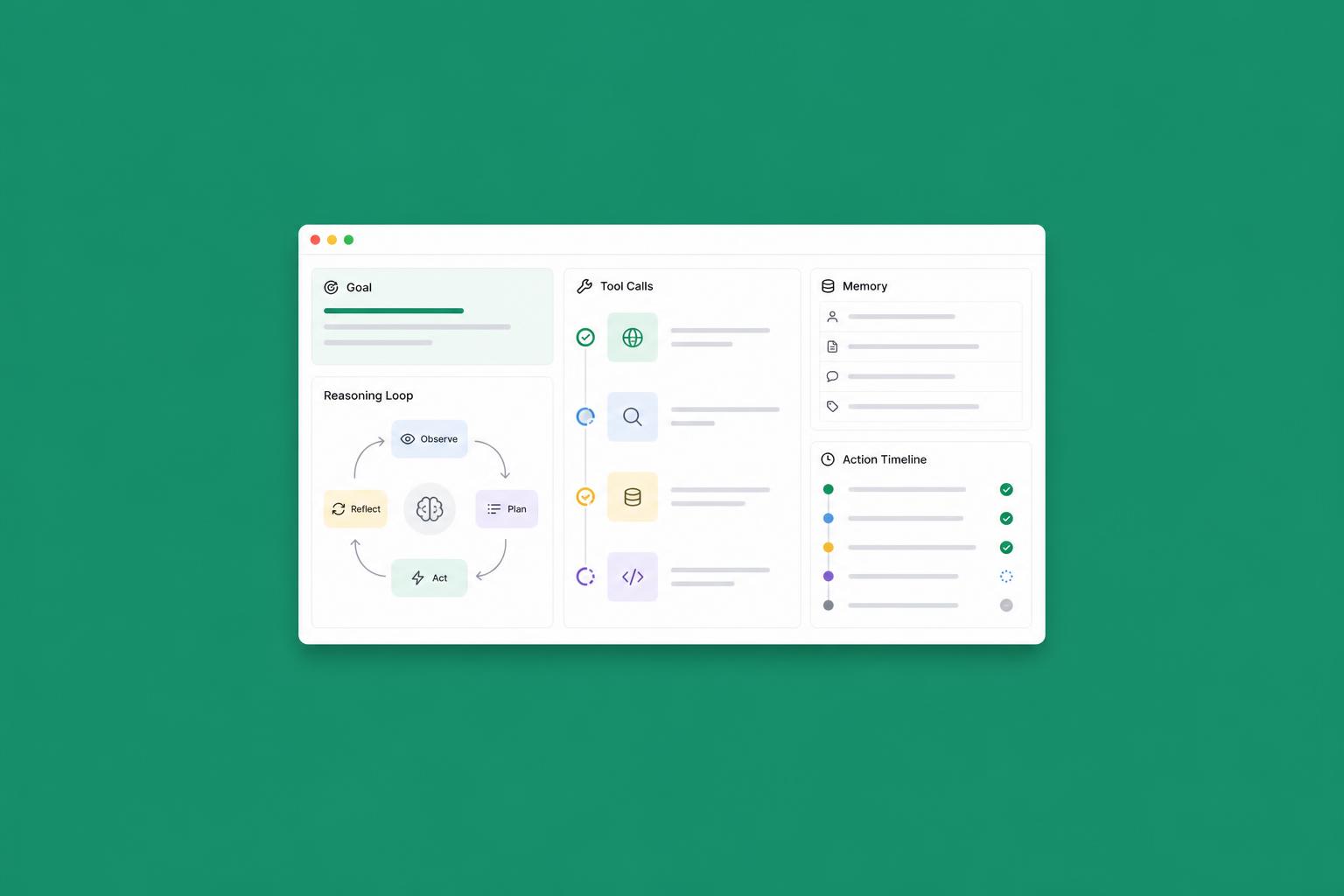
Una volta scelti modello e tool, il cuore dell'agente è il loop di esecuzione. La forma più solida che vedo in produzione è ancora il pattern ReAct esteso: il modello riceve l'obiettivo, decide se rispondere o chiamare un tool, riceve il risultato, aggiorna il suo stato interno e ripete. Sembra banale, ma tre dettagli fanno la differenza in termini di affidabilità: un limite esplicito di iterazioni (12–20 per task complessi), un meccanismo di self-check ogni N step in cui l'agente rilegge il proprio piano e dichiara se è ancora sulla strada giusta, e un fallback umano per i casi in cui la confidenza scende sotto una soglia.
La memoria è l'altra leva che separa gli agenti che 'funzionano in demo' da quelli che reggono mesi di traffico reale. Servono almeno tre livelli: memoria di sessione (contesto della conversazione corrente), memoria episodica (interazioni passate con lo stesso utente o cliente) e memoria semantica (knowledge base aziendale interrogata via retrieval). Nel 2026 la combo più solida è Postgres + pgvector con embedding Gemini Embedding 2 o text-embedding-3-large di OpenAI. Per agenti che devono ricordare migliaia di conversazioni, soluzioni come Mem0 o Letta gestiscono compaction e decadimento delle memorie senza che tu debba scrivere logica custom.
Per il framework, la scelta dipende dal linguaggio e dalla complessità. In TypeScript, la combinazione Vercel AI SDK + MCP client copre il 90% dei casi d'uso e si integra in modo pulito con TanStack Start, Next.js o un'edge function. In Python, LangGraph è ormai la scelta standard per agenti con grafi di stato espliciti e branching condizionale; PydanticAI è preferibile quando la priorità è la validazione tipata degli output. Evita di partire da framework monolitici tipo Auto-GPT o agenti 'no-code' generalisti: il debugging diventa proibitivo non appena la logica supera i tre step.
Il deploy in produzione apre la fase più sottovalutata: osservabilità. Un agente è un sistema non deterministico che chiama tool esterni, e senza tracing strutturato qualsiasi bug diventa una caccia al fantasma. Strumenti come Langfuse, Helicone o Phoenix Arize ti danno timeline complete di ogni run, costo per step, latenza per tool call e replay deterministico delle conversazioni andate male. Considerali obbligatori, non opzionali, dal primo deploy.
Sul fronte costi, nel 2026 la regola pratica che applico in consulenza è semplice: budget di token per task, non solo per modello. Un agente customer support che chiude un ticket dovrebbe costare 0,05–0,15 dollari a esecuzione; un agente sales che qualifica un lead 0,20–0,50; un agente di sviluppo che apre una PR può arrivare a 2–5 dollari ma deve sostituire ore di lavoro umano. Se sfori queste soglie di un ordine di grandezza, il problema è quasi sempre architettura: troppo contesto inviato a ogni step, retrieval non filtrato, oppure un modello premium usato dove ne basterebbe uno medio.
Le tre trappole più comuni che vedo nei progetti del 2026 sono le stesse di sempre, solo travestite. Prima: usare Opus 4.8 o GPT-5.5 per tutto, anche quando un modello mini chiuderebbe il task con qualità equivalente. Seconda: non separare il piano dall'esecuzione, lasciando che il modello decida tutto in un unico prompt monstre che diventa impossibile da debuggare. Terza: trattare l'output dell'agente come oro colato, senza un livello di validazione strutturata (Zod, Pydantic, JSON Schema) che intercetti hallucination prima che arrivino agli utenti.
La mia raccomandazione pratica per chi parte oggi è di costruire la versione zero in un pomeriggio: un modello, due tool, un loop di massimo dieci iterazioni, output validato. Mettilo davanti a utenti reali per una settimana. Misura cosa funziona, dove l'agente sbaglia e quanto costa per esecuzione. Solo dopo questa baseline ha senso aggiungere memoria di lungo termine, sub-agenti, planner separati o pipeline RAG complesse. Tutto il resto è ottimizzazione prematura — e nel mondo degli agenti la ottimizzazione prematura non costa solo tempo, costa anche token.