Agenti multimodali 2026: voce, video e azioni reali
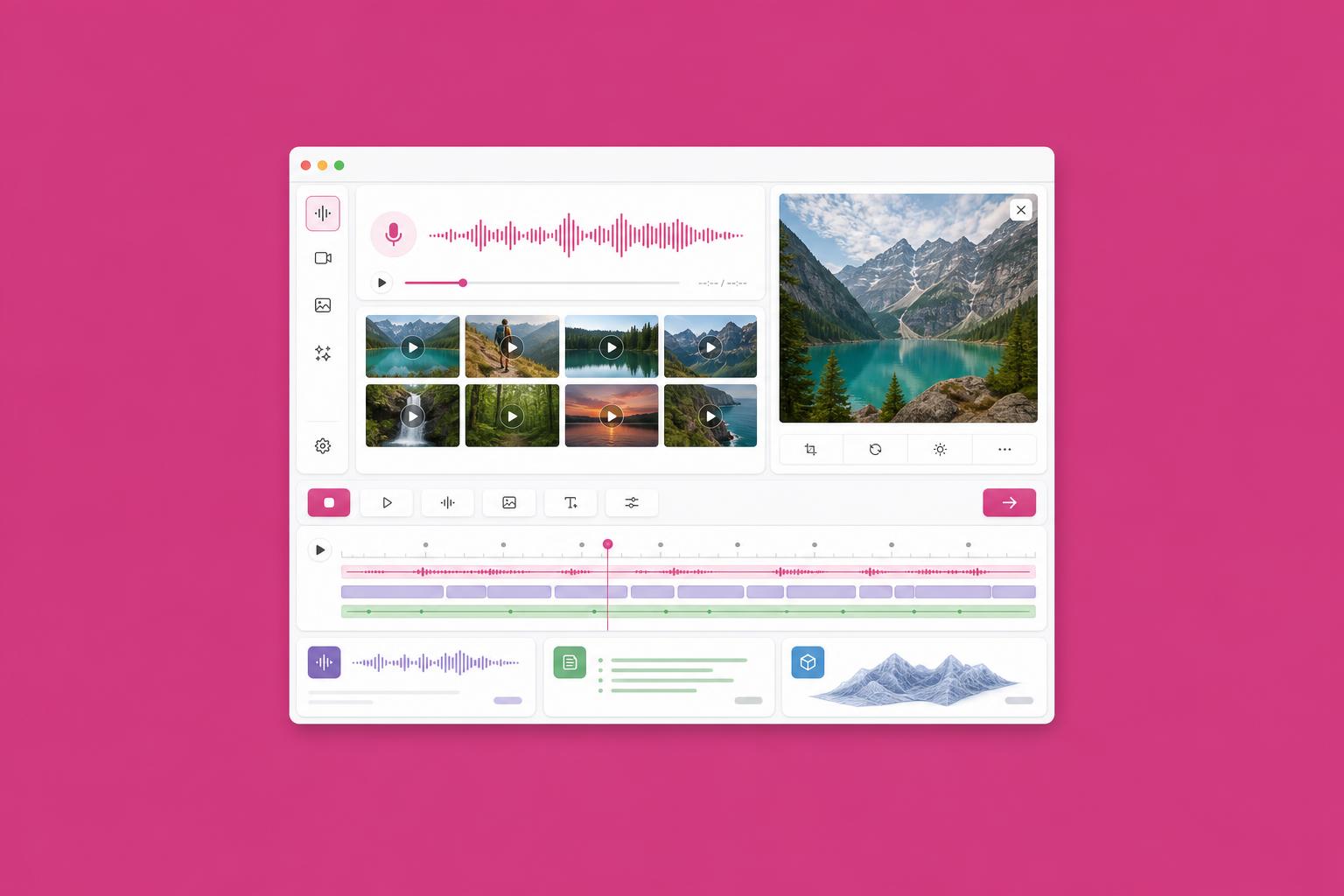
Il 2026 è l'anno in cui gli agenti AI smettono di essere solo 'chatbot con tool'. La nuova generazione di modelli multimodali combina voce in tempo reale, comprensione video continua e controllo di interfacce grafiche in un unico reasoning loop.
OpenAI Realtime, Gemini Live e Claude Voice hanno tutti raggiunto latenze sotto i 200 ms su conversazioni vocali full-duplex, abilitando casi d'uso come receptionist virtuali, agenti commerciali outbound e assistenti operativi sul campo.
Sul fronte video, modelli come Gemini 3 Vision e GPT-5o riescono a processare stream continui a 30 fps mantenendo coerenza temporale per ore — fondamentale per applicazioni di videosorveglianza intelligente, quality control industriale e training di operatori.
La parte più interessante è il 'computer use': agenti che vedono lo schermo, capiscono l'interfaccia e cliccano. È ancora imperfetto, ma per task ripetitivi su software legacy senza API è già una rivoluzione. Anthropic Computer Use è arrivato alla v3 con accuratezza superiore al 90% sui benchmark interni.
Il messaggio per chi sta progettando prodotti AI è chiaro: non pensate più in termini di 'chat'. Pensate in termini di 'agenti che vedono, sentono, parlano e agiscono'. La UX dei prossimi anni sarà tutta qui.
Articoli correlati

Scandalo xAI: Grok Build caricava le repository degli sviluppatori sullo storage di Elon Musk a loro insaputa

Kimi K3: il modello AI cinese open source che si posiziona #1 su Frontend Code Arena e fa tremare OpenAI e Anthropic
